

On February 25, Fastly shared the first part of their speaker series on security with Alex Pinto, Chief Data Scientist of Niddel and leader of the MLSec Project. The topic of his presentation was data science machine learning and security. The biggest issue that Pinto wanted to address is the marketing fluff that surrounds A.I./machine learning and security.
A lot of companies use “machine learning” as a buzzword to seem current with their trends, but Pinto stresses that this just hurts buyers and investors who know don’t know if they are buying the correct products or funding the right developments. He stressed awareness over certain heavy-handed marketing terms such as:
- Big data security analytics
- Hyper-dimensional security analytics
- 3rd generation artificial intelligence
- Secure because of math
- Math>Malware
All of these tend to be used as marketing terms without much backup on the details. Big data security analytics is usually sold as a big mythical creature that promises you nothing will go wrong and all the problems that others can’t solve, they can. The big issue with this and the reason it needs to be address is because without the right security features, your network could suffer lasting damages and extensive costs.
Difficulty of Evaluation
One of the main problems that comes with security is questioning whether your system is fully protected or not, and a lot of this has to do with the fact that many security people don’t share information. Public data sets are incredibly scarce in this industry, which makes having a benchmark of your protection a lot more difficult.
Anomaly Detection
Pinto then began discussing the issues that arise when using anomaly detection with machine learning. To begin, anomaly detection works best for well-defined processes on simpler systems. Using anomaly detection compares known means to the system, which makes it good at looking at single, consistently measurable variables. It is often the basis for most fraud prevention or used by devops to measure against different stats on their dashboards.
The problem with anomaly detection though, is that the data tends to be too diverse. Anomaly detection is like trying to measure a distance, so if a piece of data is way outside of the normal range, you know based on the distance that it is problematic. But the more dimensions you add, the more ways you have to look at the data, which means that these distances begin to look the same.
For instance, Pinto brought up this analogy–say there is square with a circle overlapping it and you want to find the distance from the center of the square to the edge of the circle. It’s pretty easy and straightforward. Now say that you have a cube with a sphere over lapping it–suddenly the distance becomes meaningless with increased volume and dimensions.
People using anomaly detection have a bunch of small models with small dimensionalities, but when you add more, detection becomes tricky and the system becomes vulnerable. For instance, consider normality-poisoning attacks. Your system is designed to compare your data to a “normal” preset, but what is the perfect normal? It doesn’t matter how you train the model, if it’s told the wrong information in the beginning, it will never learn the right way.
The Anomaly Detection Pyramid
Pinto goes on to breakdown his basic pyramid of importance when it comes to different factors that decide how to integrate machine learning anomaly detection.
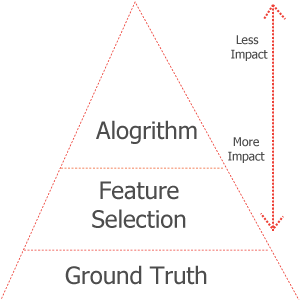
Pinto stresses that the main issue most systems have is insufficient ground truth. You could have the most extensive set of features and the best algorithm, but if the system doesn’t have specifics to compare the data to then none of it matters. When it comes to unsupervised machine learning algorithms, they don’t have the ground truth to compare their information to, which Pinto calls “lazy.”
Without any ground truth, you don’t have control over the base knowledge, which means your security can easily be compromised by attackers. Unsupervised anomaly detection may be great for exploratory matters and learning what you should build, but otherwise it should never be put into production.
Supervised Machine Learning
What Pinto recommends for security is implementing a supervised machine learning system, which improves security by trying to establish a wider ground truth. He claims that there is a good amount of data out there for malicious content to compare to your system, but that vetted non-malicious data is still a challenge. TImeliness is also a big challenge since you have to continuously train the model, but this has become easier with open source software.
When it comes to malware data, they’ve had a lot more success in clustering malware samples, which means that if you know something is bad, it is easy to detect, but classifying them without the knowledge beforehand has been less successful.
Many state of the art AV companies, though, have an absurd amount of samples. They’re been researching and consolidating data on them for decades, making machine learning anomaly detection much better. Pinto urges that you should still be careful though, because some papers that have surfaced suffer from bad ground truth.
There have also been advancements in using network-based data, such as DGA classification and domain classification in general malware network behavior, using that to train a supervised machine learner, but it has proven more difficult for developers who are currently working on it.
There’s also a focus on using threat intelligence data, mimicking the way an analyst would use this info to come to the same conclusion they would in the domain. Basically, by describing the relationship between known bad data on the internet, you can uncover the hidden links between specific actor infrastructure just like and analyst would.
Also one last buzzword Pinto notes to be weary of is the phrase “Deep Learning.” What it is in layman’s terms is premature optimization. Again, though, if you don’t have good ground truth, optimizing your system will do nothing for you.
You should remember when it comes to optimization that most security-based data is messy, very categorical, contains lots of missing values and that the actual model accuracy is a tiny component in a soulutions success. Overall, when considering machine learning Pinto suggests making sure you have an answer to the following four questions in order to confirm that you are using it for the betterment of you system
- What are you trying to achieve with adding ML to the solution?
- What are the sources of ground truth for you models?
- How can you protect the features and ground truth from adversaries?
- How does the solution and processes around it handle false positives/false negatives?