

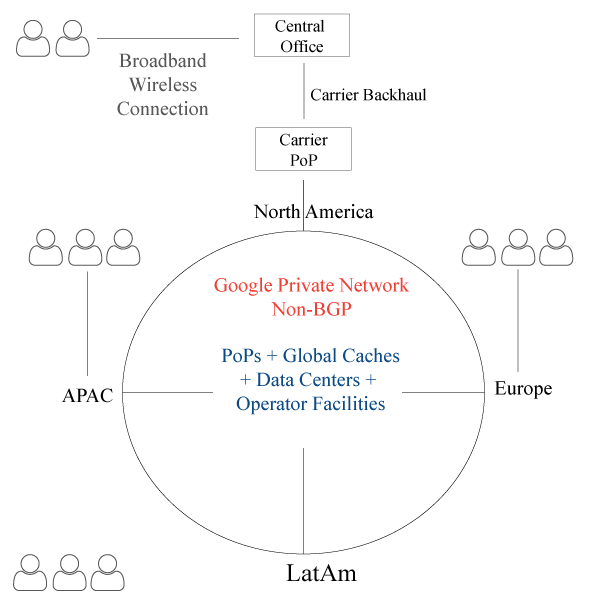
Google doesn’t play by the same set of rules that ISP’s, Carriers, CDN’s, and others play by. Sometime next year, will Google abandon BGP once and for all within their core? To date, Google has the largest private network in the world that carries 20-25% of all Internet traffic, hundreds of Global Cache Locations, 15 data centers, 90 PoPs, and they’re just getting started. Their facilities blanket the global map, unlike anything or anyone in the past.
Google data centers are connected via a private WAN known as Espresso that uses a custom routing protocol to deliver packets to/fro within their network. Espresso leverages a custom BGP stack, packet labels, and high performance messaging system to route packets based on performance data, as opposed to forwarding it to the closest neighbor. Google is a highly secretive company, and we can bet there is a lot more under the hood than what’s being announced, which will be revealed in due time. In the world of CDN infrastructure, the war between private WAN and overlay networks continues, however, we know there is no comparison because private networks trounce overlay networks like Akamai’s Sureroute. That means once a request reaches the Google peering edge, it gets routed over a high performance private network vs a slower CDN overlay network. Google Espress0 didn’t happened overnight. The process begun years ago and Google Espresso is the representation of Silicon’s Valley distaste for all things BGP. It doesn’t end there, when Google makes a big splash, the four giants follow suit.
That would be Apple, Facebook, Amazon and Microsoft, which we refer to as GAFAM, the $3 trillion juggernaut that’s wreaking havoc on the traditional business model within the networking, server, database and storage industries. This leads to one question – will Google move off of BGP completely within their core (defined as origin to the peering edge) by the end of next year? It’s very likely. If you’re a CDN its best to plan for the worse because Google is going after that market.
Google is challenging the very concept of the global network and CDN business model, which they can do because they have unlimited funds, a strong desire to destroy legacy business models, and an incredible appetite to own the data and flow of data end-to-end. Some believe that BGP is the slowest routing protocol in the networking stack, being almost 30 years old, invented in the time of pre-Cloud, pre-iPhone, and pre-IoT, thus Google Espresso is the first attempt to break away from the concept of BGP, at least at its core. Bottom line – Google has a competitive advantage over the competition, because building a global private WAN is an expensive proposition, let alone having the business model to generate enough revenue to support it.
Therefore, the non-GAFAM crowd must find new ways to route traffic via hybrid networks comprising of BGP and custom routing, that is if they wish to remain competitive. Google is the biggest threat to the CDN Ecosystem, followed by AWS, and both are vying to become the default underlying infrastructure that powers the global technology industry in the areas of compute, storage and delivery. We applaud Google for their creativity in trying to change the rules of the game when it comes to global networking and content delivery.
Post Mortem: 12/14/17
Its been almost seven months since we published this post. A lot has happened during this time. Now we can look back and ask the question – were we right or wrong in our assessment? We were wrong because BGP is still going strong and will do so for many years. And we were right because Facebook just introduce the Open/R routing platform. In their announcement, they state the following:
While traditional routing protocols have worked well over the past 30 years, it can be challenging and time-consuming to quickly push new protocols into networking devices.
And “most protocols were initially designed based on constrained hardware and software environment assumptions from decades ago. To continue delivering rich, real-time, and highly engaging user experience over networks, it’s important to accelerate innovation in the routing domain.”
And “we are excited to announce that we have been working with several external partners to bring Open/R to production, both inside the Facebook network and externally.”
What does this exactly mean? Facebook hates protocols and standards that are decades old. BGP happens to fall in that category. And they are going to do everything in their power to force change on the protocols being used within the networking industry. So far, they have been successful in challenging the hardware and networking incumbent industries with their Open Compute Project and Telecom Infra Project. Therefore, they are likely to do the same with networking protocols.
Now this poses an interesting question. Who is leading the way in creating a new routing ideology that will force change upon the industry. Google and Facebook are tied, but other GAFAM members are likely to join the party soon. The giants have a herd mentality when it comes to challenging incumbent industries and players, so together, they might be able to pull it off. Regardless, whatever happens happens, it doesn’t bother us because we don’t sell networking hardware or services.