

The Stateful CDN is a model that incorporates a distributed database into the technology stack. The purpose of the CDN database is to provide state to stateless services such as edge functions, edge containers, and serverless. Cloudflare is the first startup to introduce a CDN database. In due time, more CDNs will follow. This post is a high-level overview of NewSQL and emerging CDN database.
A few years ago, building a distributed SQL database with strong consistency and ACID compliance was extremely difficult. Some tried but failed. Because of the rigidity of SQL architecture, NoSQL emerged as an alternative. Companies like Google and Amazon sacrificed consistency for availability because it meant they could scale horizontally and add millions of clients.
Then Calvin happened, followed shortly thereafter by Google Spanner. The thought leaders behind Calvin and Spanner introduced a novel approach to building a distributed database that incorporated strong consistency and high availability. As a result, a new crop of startups popped up that followed in their ways.
For this first time, startups and CDNs have the tools and information to develop a CDN database that has strong consistency and high availability, globally. Academia and startups have published deep insight on the subject, in the form of white papers, videos, and blog post.
We have identified three startups that are leading the movement of the distributed SQL database. Although these startups have built some parts of the database from scratch, many incorporate existing technologies like RocksDB storage engine and raft consensus.
|
Fauna |
Cockroach |
Yugabyte |
|
| Founded |
2012 |
2015 |
2016 |
| Total Raised |
$32.6M |
$53.5M |
$24M |
| # of Employees |
43 |
77 |
36 |
| Type |
Multi-model |
NewSQL |
Multi-model |
| Derivative |
Calvin |
Spanner |
Spanner |
Source: Crunchbase and LinkedIn
The distributed SQL database movement is disruptive, vibrant, technical, and entertaining. Vendor disagreements over technology architecture are aired in public. Debates are positive for the global community because they provide rich perspective and diversified viewpoints.
Calvin and Spanner
In 2007, Amazon published the Dynamo paper, an important research paper that described a new type of database, the key-value store known as DynamoDB. The paper was an important milestone for the industry because it detailed their approach to building a highly available database.
In 2012, two more important papers were published, Calvin and Google Spanner, one right after the other. Both papers were also an important milestone that helps create a new market in the crowded database industry, the distributed SQL database. The papers helped start a movement involving startups that are now challenging the cloud giants in the database market.
- Dynamo Paper: Amazon white paper on their NoSQL database
- Calvin Paper: Yale academics published research on a new kind of distributed system
- Spanner Paper: Google white paper on their NewSQL database
As a result of the Calvin paper and Google Spanner paper, two different camps erupted with opposing database philosophies. The camps are known as the Spanner derivatives and Calvin derivatives.
Background
Before continuing, basic terminology and concepts will be reviewed. The database market is full of jargon. Understanding the basics helps in evaluating vendor differences. For example, Cloudflare Workers KV is a key-value data store that is highly available, eventually consistent, not ACID compliant, and lacks a consensus protocol. Thus, the last three properties indicate a weakness in the architecture.
- SQL Basics
- High Availability
- CAP Theorem and ACID Compliance
- Consistency Levels
- Consensus Protocols: Paxos vs Raft
- Calvin vs Spanner
- LSM vs B-Tree
SQL Basics
An SQL database is a collection of facts that are recorded into tables. The table organizes data into rows and columns. A distributed SQL database is horizontally scalable, capable of running on multiple nodes, in different regions, and is ACID compliant. The database has three parts: entities, attributes, and relationships. The entity is an object such as a person, place, or thing. For example, an e-commerce database might have a Customer Table, Order Table, and Products Table.
In the first row of the Customer Table is the customer ID, followed by the name, address, etc. Likewise, the first row in the Order Table is order ID and Product Table is product ID. The first row of “IDs” in the table is called the primary key. The primary key is important and must be unique, in order to avoid duplicate entries of the same object, like when you have two John Doe’s, but they live in different cities. The primary key is usually located in the first column. The schema defines the relationships between tables. Schema tools help database designers build relationships amongst tables. A task like a customer checking an Amazon order will require data from multiple tables.
Users interact with the database through a query language called SQL (structured query language). SQL statements are used to store and retrieve data from the database. Another important feature is the index, like the index in a book. The purpose of the index is to point the query in the right direction. This ensures queries perform fast. Without indexes, queries would take forever, as it would have to search many rows for the answer. The primary index will access records by primary key and secondary index by a non-primary key such as a name.
- Entity: object name for person, place, or thing
- Table: rows and columns that organizes data
- SQL: a query language used to store and retrieve data
- Primary Key: unique identifier like an employee ID
- Foreign Key: the primary key used in another table
- Index (Primary): access a record using the primary key
- Secondary Index: access a record using a non-primary key
- Schema: the relationship between tables
High Availability
High availability comes in different flavors. Four methods are clustering, sharding, replication, and partitioning. Although there is confusion as to what is partitioning and sharding, it’s basically the same, to divide the database into chunks and spread them across servers or regions. Clustering and replication are also used to build high availability into database architecture by sharing the data across multiple nodes. In the early days, Google sharded it’s MySQL database into chunks for the Adwords platform, in order to improve performance.
- Clustering: Sharing data across two or more nodes
- Replication: Create a database copy and store on multiple nodes
- Sharding / Partitioning: Divide database into chunks (shards/partitions/fragments)
- Horizontal Sharding: Divide tables by rows and stored on different nodes
CAP Theorem and ACID Compliance
CAP theorem states that a distributed data store can only have 2 of 3 properties. The properties are consistency, availability, and partition tolerance (network failure). As a result, designers were forced to pick a combinations of CA, CP, and AP.
Another important feature of the SQL database is ACID compliance. ACID is a set of properties that guarantee transaction validity in the event of errors. ACID was coined by Theor Harder and Andreas Reuter in 1983.
CAP theorem was introduced in 1998 by Eric Brewer, a computer scientist who now works for Google. He previously co-founded Inktomi. Inktomi is the startup that developed the famous Traffic Server, which eventually became the Apache Traffic Server.
- CAP: Consistency, Availability, and Partition Tolerance
- ACID: Atomicity, Consistency, Isolation, and Durability.
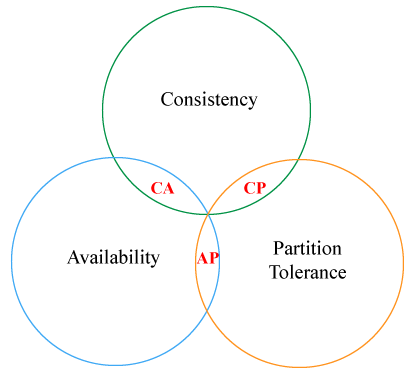
Recently, the decades-old CAP theorem has come under assault. Eric Brewer, the author of CAP stated his reasons in a white paper. Also, Daniel Abadi, author of Calvin paper stated that CAP theorem falls short in two areas: availability and partition tolerance, as these two are asymmetrical with no difference between CA and CP systems.
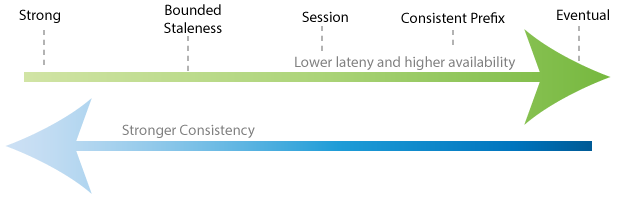
Consistency Spectrum
There are five levels of consistency. Strong consistency is the “gold standard” of the industry and eventual consistency is the weakest form. Building consistency into a database architecture is about trade-offs. When a database has strong consistency, that means there is a sacrifice in latency and availability. Eventual consistency provides higher performance and higher availability, at the cost of weaker consistency. Therefore, choosing the right consistency level depends on the use case. For banking, strong consistency is a must. For storing cat images, eventual consistency is ideal.
Consensus Algorithm Protocols
The consensus algorithm protocol is a key part of the distributed database architecture. When there are multiple nodes performing parallel writes, consensus helps the network come to an agreement on value. In a present-day network, when nodes sitting in different regions perform parallel writes, coming to a consensus is challenging. Paxos and Raft help with that process. Timestamps are one of the metrics used to order writes.
Paxos was developed by computer scientist Leslie Lampert who now works for Microsoft. In 2001, he published the Paxos paper. Raft was developed by Stanford academia, and it is the easier of the two protocols to use.
Basically, Raft uses an election process whereby follower nodes elect a leader. The leader is responsible for managing the write request. Every follower sends the write request to the leader, who then organizes writes and commits. There can only be one leader at a time. If the leader node fails, the followers elect a new leader.
- Paxos: Google Spanner
- Raft: Yugabyte, Fauna, and CockroachDB
Startups
In this section, three startups are evaluated. Two are derivatives of Spanner and one of Calvin. The Spanner derivatives are Yugabyte and CockroachDB. Fauna is the Calvin derivative.
Yugabyte and CockroachDB both use RocksDB, a persistent key-value storage engine developed at Facebook, then open sourced. RocksDB is an engine, not a database, although it has DB in its name. RocksDB was designed using LSM (log-structured merge trees), which is optimized for heavy write workloads, vs Btree, which optimizes for heavy read workloads. Below is a summary of vendor features. This is not a comprehensive vendor comparison. Startups are listed in order by year founded.
Fauna
Fauna started in 2012, raised $32M, and has 43+ employees. They’re a Calvin derivative and call their product the relational NoSQL. At its core, FaunaDB is a NoSQL system that has some relational database properties. The founding team worked at Twitter and Professor Daniel Abadi (Calvin Paper) is an advisor to the company. One of the primary differences between Fauna and the Spanner/derivatives is in the use of timestamps and ordering of transactions. Spanner uses TrueTime and Fauna uses a preprocessing technique. Below is a summary of the feature set.
Features
- Calvin derivative
- Multi-model data model
- 100% ACID
- Uses strict serializability
- Does not use physical clock synchronization for consistency
- Schema-free and object-relational model
- Unified consensus
- Works inside containers
- One global transaction log organizes writes
- Cloud-based and on-prem licensing
- Masterless, multi-cloud, active-active clustering architecture
Cockroach Labs
Cockroach Labs started in 2015, raised $53M, and has 77+ employees. They’re the first Spanner derivative and an SQL database at its core. The founding team worked at Google, hence, the decision to build a Spanner like product. The Cockroach team has done extensive comparisons to the competition like Amazon Aurora. The startup claims that version 2.1 is 50x more scalable than Amazon Aurora. That’s great, if it doesn’t cost 50x the price tag of Aurora. All kidding aside, even if Cockroach is half right, being 25x faster than Aurora at the same price tag or less is impressive.
Features
- Spanner derivative
- SQL system
- ACID Compliant
- Works in container
- Sometimes compatible with Postgres
- “Claims” AWS Aurora cost 10x more for OLTP workloads
- Uses RocksDB storage engine
- Auto-sharding and per shard consensus
Yugabyte
Yugabyte started in 2016, raised $24M, and has 36+ employees. They’re a Spanner derivative and an SQL database at its core. The founding team worked at Oracle, Facebook, and Nutanix. One of the reasons the team decided to model their database after Spanner, Spanner has been battle tested at Google for ten years prior to release. One of the database features, its fully compliant with Postgres, the second most popular open source SQL database. That means Postgres users can use the SQL commands on Yugabyte.
Features
- Spanner derivative
- Multi-model data model
- ACID Compliant
- Uses RocksDB storage engine
- Work inside containers
- Compatible with PostgreSQL
- Auto-sharding and per shard consensus
- Supports YSQL and YCQL
The CDN Database
The CDN database is the latest feature that will transform the industry, much like cloud security. Cloudflare and the NewSQL startups are introducing innovative features that will dramatically improve the performance of edge functions and edge containers.
Database-as-a-Service (DBaaS) is a form of CDN, the only difference, DBaaS is state and CDN stateless. The NewSQL startups are teaching the global community a few lessons about distributed database architecture.
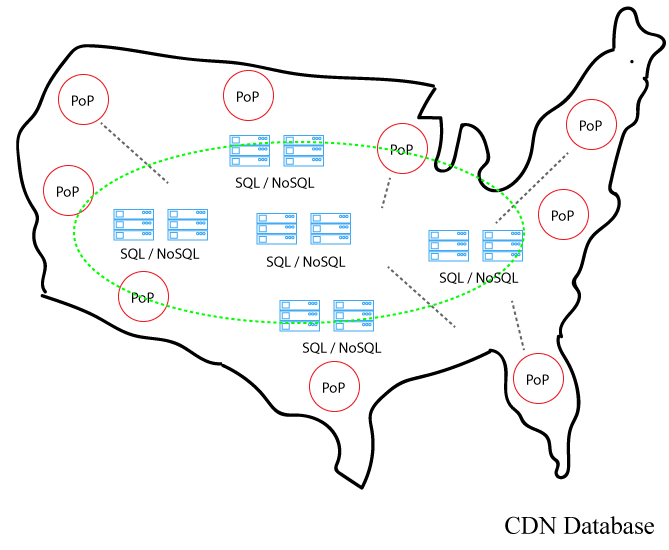
Here’s a few takeaways to consider when designing the CDN database.
First, start simple. There’s no need to deploy a database node in every PoP. Instead, divide the global map by regions (North America, EU, APAC, and LatAM) and place nodes there. In each region, ensure nodes are distributed evenly. For example, in the US, place nodes on the west coast, east coast, middle America, etc. Database shard per region?
Second, connect database nodes with MPLS, VPLS, or point-point connectivity. Stay away from the public internet. Since most PoPs are in Equinix data centers, it should be relatively easy to purchase connectivity. Also, there are companies like Megaport and Packetfabric that specialize in connecting data center sites. Another benefit, all carriers offer SLA’s with latency guarantees on WAN connectivity.
Third, the database cannot run on AWS. Instead, it must run in the same PoPs that house caching servers. For the CDN, PoPs are usually located at the major peering exchanges. The two benefits of this arrangement: 1) database performance over the WAN (inter-data center) can be optimized continuously. In order to do that, CDNs must own the routers and run their own BGP network 2) CDNs will increase their profit margins. No need to share profits with AWS.
Fourth, leverage some of the existing open source technologies developed by the community, such as RocksDB and Raft.
Fifth, incorporate strong consistency into the CDN database and ensure its ACID compliance.