
The rapid growth in AI is having a big impact on the development and sale of specialized chips. Allied Market Research noted in the Artificial Intelligent Chip Market Outlook that AI chip sales are predicted to grow from $6.6B in 2018 to $91B by 2025. The AI chip giant of the industry is Nvidia. However, the competition is heating up as Google, Amazon, AMD, Microsoft, IBM, and Samsung build competing products.
Even Facebook has jumped into the market. Earlier in the year, Intel announced it was working with Facebook in developing a new AI chip that is due to come out at the end of 2019. Facebook is a pioneer in open source software, AI (PyTorch), open source telecom hardware (Telcom Infra Project), and open data center design.
In addition, there are dozens of startups like Cerebras that are focused strictly on AI. Cerebras has developed “the largest chip ever built” that is 56x bigger than the largest GPU and comes with 400,000 AI-optimized cores. Here is a list of companies that have/are developing AI chips.
AI Chip Companies
Adapteva | AMD | Cerebras | Facebook | Google | Grapahcore | Groq | Imagination | IBM | Intel | Kalray | MediaTek | Mythic AI | Nvidia | Qualcomm | SambaNova | Samsung | Thinci | Wave Computing | Xilix
GPU, TPU, and FPGA
AI models like deep learning are compute-intensive. The right architecture is needed for AI and a high quantity of cores is required to process computations at scale. More specifically, AI hardware must be able to perform thousands of multiplications and additions in a mathematical process called matrix multiplication. Instead of describing what is matrix multiplications, it’s better to show it.
Matrix Multiplication
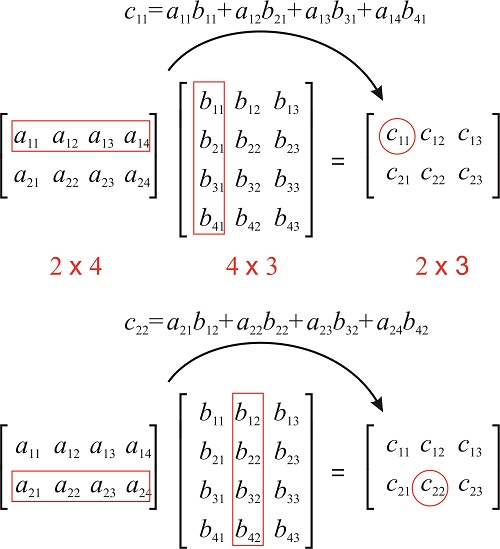 source: Marica Levitus at AZU
source: Marica Levitus at AZU
Matrix multiplication plays a big part in neural network computations, especially if there are many layers and nodes. In the illustration below, there are six layers, 25 nodes, and thousands of connections between the nodes, by the looks of it. This would be a considered a compute-heavy model.
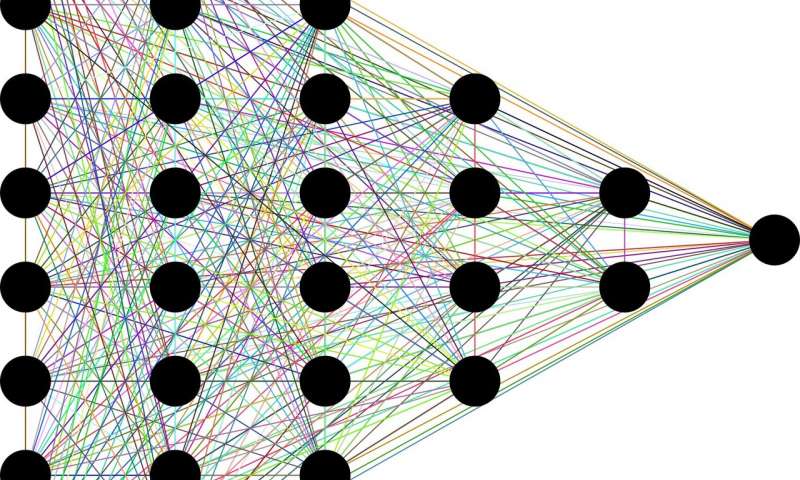
Matrix multiplication is the operation that cofounds the CPU. CPU’s were designed as general-purpose chips that can run any application on the desktop or server. At the most basic level, the CPU is able to process one task at a time. The GPU makes up for the deficiency in CPU architecture by adding thousands of CUDA cores and hundreds of Tensor cores, depending on the card, that can process thousands of tasks in parallel.
However, for some like Google, the GPU is still too general-purpose to run AI workloads efficiently. Thus, Google has developed its own AI hardware known as the TPU. Google describes the TPU as a “custom ASIC chip-designed from the ground up for machine learning workloads” and it currently runs many of its services like Gmail and Translate.
Google explains the reason they decided to create the TPU. In short, the CPU architecture is based on the von Neumann architecture. Thus, “every single calculation” of the CPU is stored in L1 cache (memory). This creates the “von Neumann bottleneck” when memory must be accessed. The ALU (arithmetic logic units) is a circuit that controls memory access and it executes each transaction “one by one”. The graphic below shows the relationship between the CPU, ALU, and memory.
von Neumann Architecture
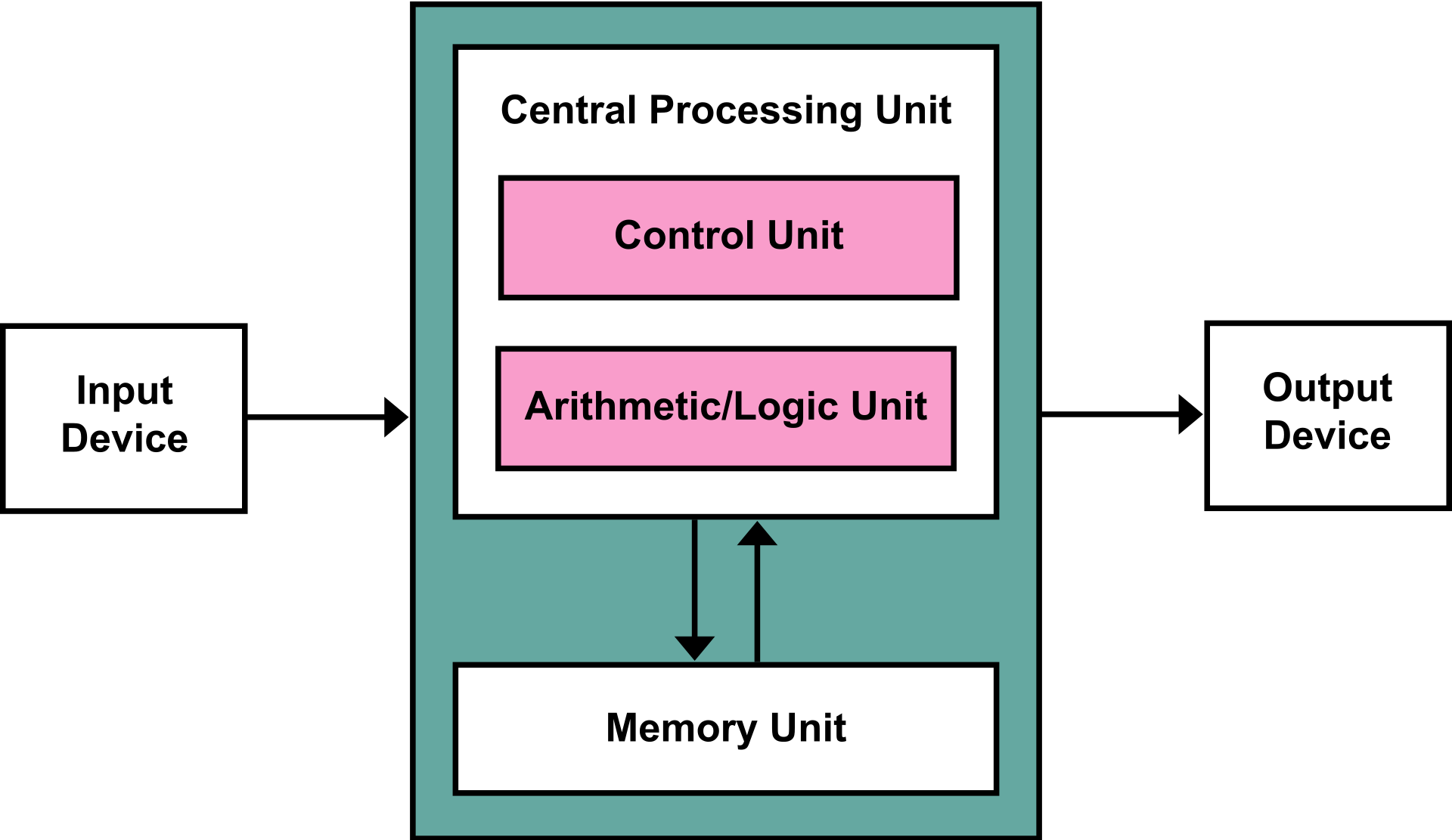
source: Wikipedia
The GPU solves this problem by throwing thousands of ALU’s and cores at the problem. However, even though GPUs process thousands of tasks in parallel, the von Neumann bottleneck is still present – one transaction at a time per ALU. Google solved the bottleneck problem inherent in GPU’s by creating a new architecture called systolic array. In this setup, ALU’s are connected to each other in a matrix. They call this arrangement the Matrix Processor. In one particular configuration, there are 32,768 ALU’s.
Not to be outdone, Microsoft has also designed its own AI architecture based on FPGA (field-programmable gate arrays). They call their hardware the Neural Processing Unit (NPU) and it powers Azure and Bing. Although FPGA has been around for decades, Microsoft has figured out a way to scale the architecture for deep learning workloads. Their deep learning platform is called Project Brainwave. The team behind Project Brainwave said the flexible architecture of FPGA allows them to write “algorithms directly on the hardware” thus bypassing “less efficient software as the middle man”. The best part, the architecture allows them to reprogram the hardware at “a moment’s notice” if changes are required due to advances in technology.