

The AI industry is making progress at simplifying distributed machine learning, defined as the process of scheduling AI workloads across multiple GPUs and machines (nodes). One of the primary benefits of distributed machine learning is its ability to reduce model training times, wherein some cases, training can be reduced from days to hours. However, when multiple users within an organization need to share GPUs, a different type of service is needed, which will be described below.
The lifecycle of distributed machine learning can be broken down into three phases. Just a few years back, distributing AI workloads, such as hyperparameter tuning or the processing of each layer (neural network) across multiple GPUs and nodes was a manual process. Ex-Zinga software architect Jonathan Hui explained in 2017 that if a machine had a CPU and GPU, Tensorflow would default to the GPU. However, if there were multiple GPUs, Tensorflow would default to the one “with the lowest ID” ignoring the rest. Thus, forcing Tensorflow to run on multiple GPUs required an “override.” Another option was to use Apache Spark with TensorFlow, where Spark would distribute workloads across multiple GPUs and nodes. The above scenario is phase 1.
Google Distribution Strategies
In order to overcome the shortcomings of distributing AI workloads in TensorFlow, Google developed distribution strategies. Distribution strategies, represented as tf.distribute.Strategy is an API that allows TensorFlow to distribute workloads horizontally across multiple GPUs and nodes, out-of-the-box, with minimal code changes. Google evangelist Gonzalo Meza explains that there are two paradigms in distributed machine learning: 1) data parallelism and 2) model parallelism. In data parallelism, workers train on different “slices” of data locally, communicating the results to each other, thus working in a concerted manner. For models that have too much data for any single node to handle, model parallelism is the ideal solution because it allows workloads to be distributed across multiple GPUs and nodes. The above scenario is phase 2. However, there is no support for sharing GPU resources among multiple users.
Google’s distribution strategy is a robust system for TensorFlow, however, it works only in the TensorFlow ecosystem. PyTorch requires its own feature called DataParallel. Thus, each AI framework requires its own method to distributed workloads across multiple GPUs and nodes, resulting in vendor-lockin in some cases.
Training Times
Why is distributed machine learning important? Because model training times can be reduced significantly by distributing AI workloads across multiple GPUs and nodes. Training time directly impacts model accuracy. However, distributed machine learning allows organizations to cheat on training times. In one example, Google TensorFlow engineer Priya Gupta demonstrated that model accuracy improved from the low 50% (percentile) to 75% when training time was increased from 30 hours to 80 hours on a 1-GPU node, as illustrated below. However, running the same model on multiple GPUs and nodes can reduce training to a few hours, theoretically.
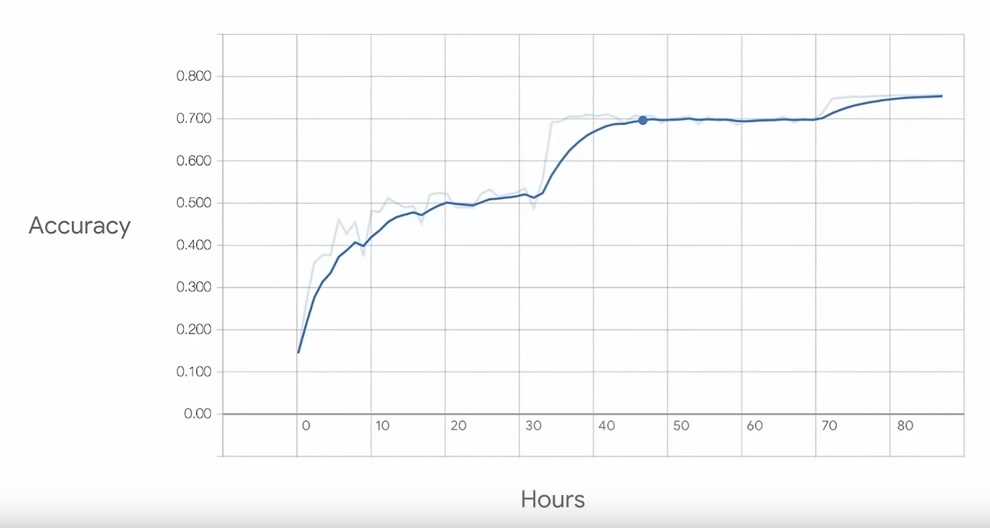
source: Google I/O 2018
Presently, a new segment seems to be emerging in the AI industry where startups are providing the ability to distribute AI workloads across multiple GPUs and nodes. Some companies like Databricks are baking this feature into their product portfolio, while others like Run.ai have created a business model around it.
Run.ai, a Tel-Aviv startup has developed a service they refer to as a “virtualization layer for deep learning training models”. In short, their platform allows enterprises to distribute machine learning tasks across multiple GPUS, nodes, and users, in an automated fashion. The startup has abstracted the hardware from the AI frameworks and inserted a layer in-between that supports distributed machine learning across TensorFlow, PyTorch, Caffe, Keras, Scikit-learn, and others.
Distribute Machine Learning Stack
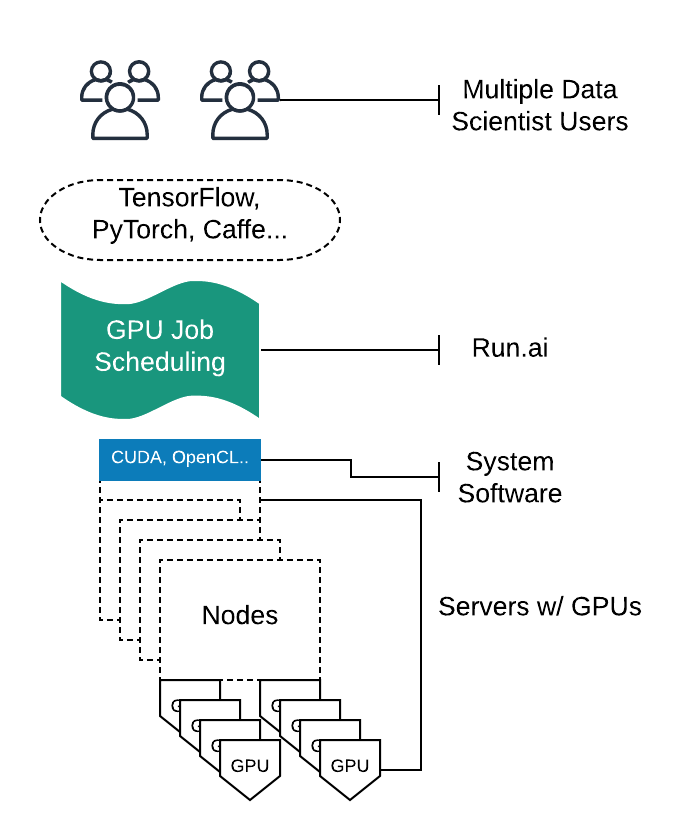
In essence, Run.ai is a feature-rich service that allows companies to share GPU resources among multiple users, schedule AI jobs across GPUs and nodes, support advanced queuing, quotas, and pause/resume, and provides the ability to monitor varoius activities. The above scenario is part 3 of the lifecycle.
Background
- Company: Run:ai
- Founded: 2018
- HQ: Tel-Aviv
- Raised: $13M
- # of Employees: 22
- Co-founders: Omri Geller (CEO) and Ronen Dar (CTO)
- Product: Distributed machine learning platform that allows AI workloads to be spread across different GPUs and nodes, while supporting GPU resource sharing among multiple users