

Database technology continues to evolve in the cloud-native era. The relational model was the ideal platform for structured data, providing ACID compliance for those who required it. However, it doesn’t scale horizontally and doesn’t work well with unstructured data.
The NoSQL database was developed to overcome these limitations, allowing companies like Google, Facebook, and Twitter to distribute workloads horizontally, inexpensively. NoSQL has different types of databases under its umbrella including key-value, document, graph, and wide-column.
Thereafter, NewSQL came onto the scene, incorporating features from both its SQL and NoSQL brethren. Still, it wasn’t good enough for modern workloads. In 2012, an earthquake shook the database market when a Yale professor and Google independently published ground-breaking research on a new type of database. This database is becoming an essential platform for storing and processing data in the edge computing era. It’s highly distributed, as in having the ability to run in regions throughout the world, yet still provide ACID compliance when necessary.
Google Spanner and Calvin
In 2012, Yale University published a research paper titled the Calvin paper in SIGMOD. Later, in the same year, Google published the Spanner paper in OSDI.
Both of these papers described the design of geographically replicated, ACID-compliant, consistent, and transactional database systems. They criticized NoSQL database systems for compromising replication consistency and transactional support.
In the papers, Yale University and Google argued that it is possible to develop extremely scalable, geographically replicated systems without giving up on transactional support and consistency. Both of these papers have heavily influenced the design of modern NewSQL systems.
However, a debate sparked when prof. Daniel Abadi, who invented the Calvin transaction management protocol, stated that NewSQL database systems are failing to guarantee consistency due to Spanner. Without Spanner’s hardware, software-only databases cannot guarantee the accuracy of distributed transactions due to clock skews. On the other hand, Calvin’s global consensus approach is suitable for all applications that demand transactional assurance in distributed databases.
According to another critical analysis, the Calvin approach is suitable when multiple transactions access the same data with high-conflict in concurrent transactions, and the volume of transactions is low. The Spanner approach is ideal for generic, concurrent transactions on non-conflicting data.
In order to understand exactly how Calvin and Spanner work, it is important to take a look at the latency-consistency tradeoff.
Latency-consistency tradeoff
With the increasing demand for 24/7 availability of modern applications, especially mission-critical apps, data systems are frequently replicated to stay up, even during a server failure. The apps need immediate failover to a replica database system, and this involves several important tradeoffs.
The most common tradeoff is CAP that refers to a tradeoff between consistency and availability during a network partition. Another lesser-known but equally important tradeoff is between latency and consistency that can take place even during normal operations.
Here is what causes this tradeoff: You cannot perform consistent replications across all replicas without synchronous network communication that takes time and leads to latency. For closely located replicas, this latency may not be inconvenient. But replication over a WAN causes significant latency.
Now, let’s talk about three general techniques for performing replication and understand latency or consistency trades off with each technique.
1. Data updates sent to all replicas in one go.
When updates do not pass through an agreement protocol, it could cause replica divergence, that is, lack of consistency since each replica may choose a different order for update application. And, if updates pass, then all replicas could agree on the order process the updates. But, this causes increased latency from several sources.
2. Data updates are first sent to a decided location.
This particular location is called the master node that resolves all requests to update the same data item. The order in which updates take place determines the order in which updates are performed by all replicas. After resolving updates, it replicates them to all replica locations.
Now, here are three options:
- Synchronous replication. The master node waits for all updates to the replica(s) before committing the update. As a result, replicas remain consistent. However, synchronous actions lead to increased latency due to the limited latency caused by the slowest entity.
- Asynchronous replication. The update is treated as completed before they are replicated. The consistency-latency tradeoff depends on how reads are handled.
- Combination of synchronous and asynchronous replication. Updates are synchronously or asynchronously to replicas. The consistency-latency tradeoff depends on how reads are handled. If reads route to at least one node that is synchronously updated, it is possible to maintain the consistency, but the latency problems exist. If reads are possible, then inconsistent reads are also possible.
3. Data updates are first performed in random locations: Then, updates are propagated to the other replicas. Here, the latency-consistency tradeoff depends on two options. Synchronous replication may cause additional latency problems to detect and resolve simultaneous updates to the same data item in two different locations.
Now, let’s explore the system architecture of Calvin and Spanner.
How does Calvin work?
Notably used by FaunaDB, Calvin is a scalable transaction scheduling and data replication protocol. It is designed to transform a non-transactional and un-replicated data store into a consistently replicated and ACID-compliant distributed database system.
The protocol supports database’s horizontal scalability and ACID-compliant distributed transactions. It also supports Paxos-based synchronous and asynchronous replication across geographically separated data centers and within a single data center.
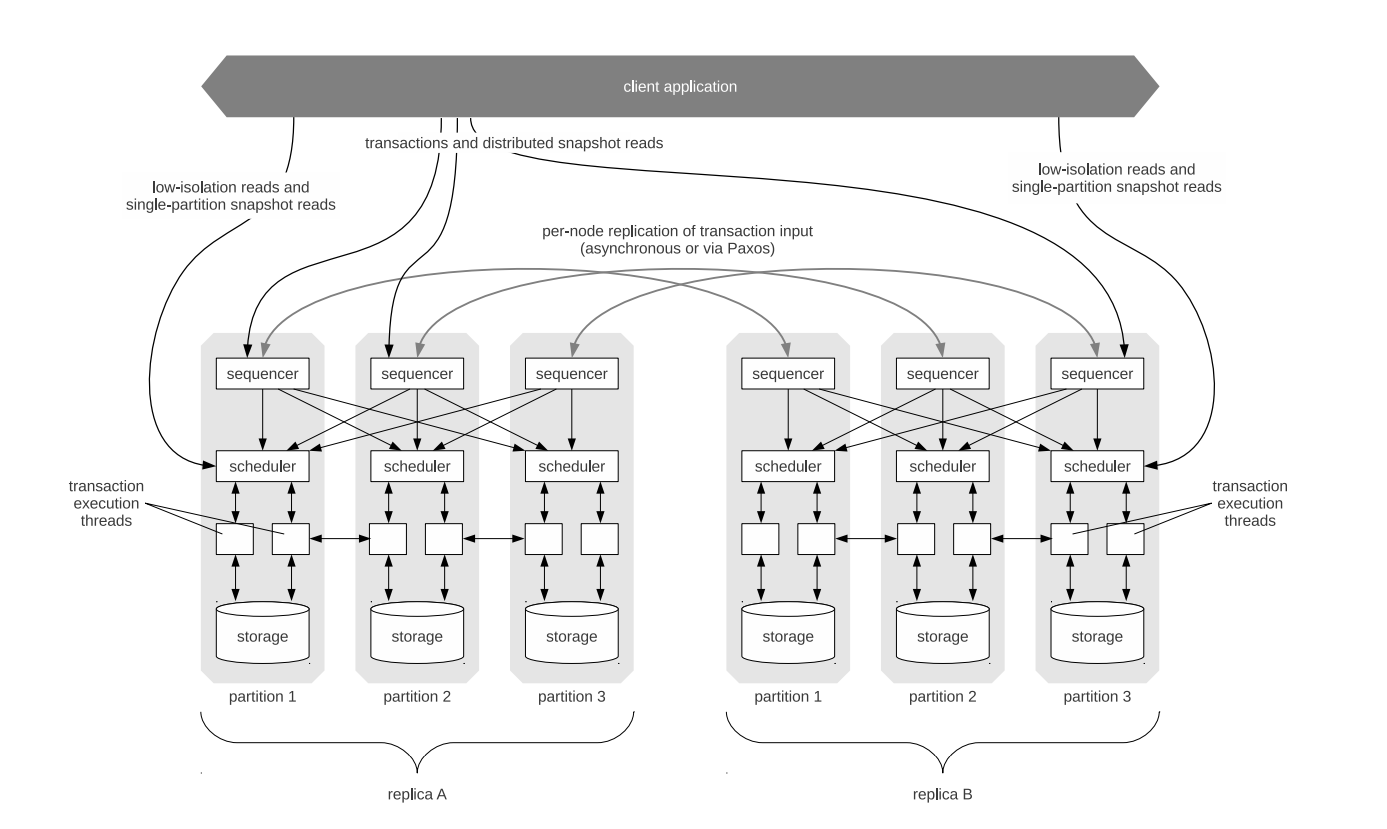
As you see in this figure, sequencers receive transactional inputs and batch write them into a global transaction log. The log’s sequence follows the order of transactions to which replicas ensure execution-time serial equivalence. Thus, the sequencers handle the replication and logging of this input sequence.
The Calvin protocol does not require 2PC through deterministic execution. The schedulers arrange execution via a deterministic locking scheme to ensure serial order equivalence specified by the sequencers. It also allows concurrent execution of transactions by threads.
Spanner applies consensus at an individual shard level, and Calvin applies it at the global sequencer level. That is why Spanner’s approach can be considered as partitioned consensus while Calvin’s approach can be considered as global consensus.
How Google Spanner Works?
Spanner is Google’s internal distributed database. It supports distributed transactions that can span multiple locations worldwide. Google created Spanner to address the limitations of Google Percolator, which is a distributed transaction system focused on a single location.
Google Cloud Platform released a subset of the Spanner, called Google Cloud Spanner, in 2017.
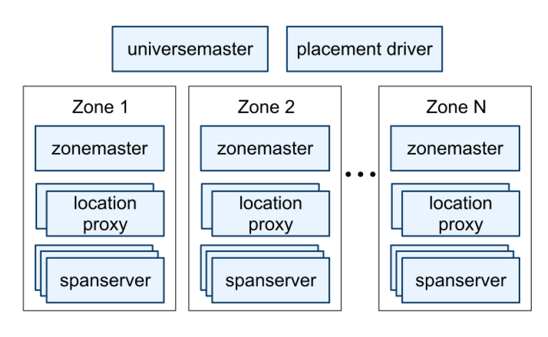
As you see in this figure, Spanner deployment is termed as a “universe.” The universe uses a Paxos group per shard to auto shards and auto balances the dataset on machines located in multiple zones at data centers existing across the world. These shards are replicated for geographic locality and global availability.
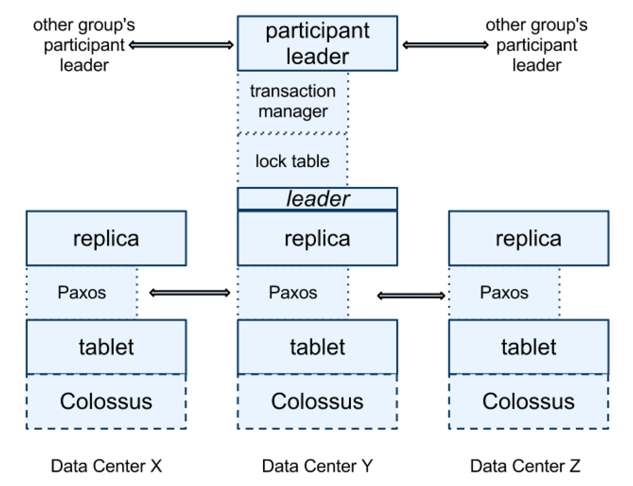
Each spanserver implements a lock table at every leader replica to support two-phase-locking concurrency control. Also, a transaction manager at the replica supports distributed transactions.
Transactions involved in only one Paxos group bypass the transaction manager because Paxos and the lock table and Paxos can handle the job. But, transactions that involve multiple Paxos groups, the leaders of those groups perform 2PC. At the same time, the state of the transaction manager is modeled as a persistent Paxos group to guarantee availability.
The most significant function of Spanner is that it achieves External Consistency. It uses the TrueTime API, which is Google’s reliable “Wall-clock” time tracking service, to assign global commit timestamps to all transactions.
Difference Between Spanner and Calvin
Most of the differences between Spanner and Calvin arise due to one most obvious difference: the ordering transactions in time.
So, let’s begin with it:
- Transactions Ordering
Spanner uses “TrueTime” while Calvin uses “preprocessing” or “sequencing” for transaction ordering.
The notion of transactional order is provided by a serializable system. Many transactions execute in parallel. However, the final state should be as if transactions were processed one by one.
Transactions that touch each other’s data should be ordered against each other. A “later” transaction should be processed against the database version that includes the modifications made by the “earlier” one.
- Locking
Spanner uses GPS and atomic clocks to synchronize time within a familiar unpredictable bound. If two transactions are executed during time periods with no overlapping uncertainty bounds, the later transaction certainly will see all the writes of the earlier one.
Before performing any write, Spanner obtains write locks, and after writing all the data, it assigns the transaction a timestamp based on the actual committed time. The timestamp is used for transaction ordering and locking guarantees timely execution.
On the other hand, Calvin uses preprocessing or sequencing for transaction ordering. It inserts all transactions into a distributed, replicated log before processing them.
Clients insert transactions into the preprocessing layer of their region, which is then submitted to the global log through Paxos, which is a cross-region consensus process. Every transaction is processed one by one in the official transaction order in the log.
- Correctness
Since Spanner assumes abounded clock skew tracking, its derivative databases ensure the correctness of distributed transactions only when the clock skew is lower than the maximum configured.
In contrast, the Calvin protocol does not even depend on clock skew. Its derivative databases can support distributed transactions with Strict Serializability isolation levels.
But, Spanner supports only a maximum of Serializability isolation level only under bounded clock skew scenarios.
- Overhead Involved in Transaction Replication
Calvin replicates transactional input only once, during preprocessing, using a deterministic execution framework that avoids cross-replication communication.
For this purpose, the preprocessor analyzes the transaction code and pre-execute non-deterministic code. Once all code is deterministic, the replica focuses on processing the transactions following the correct order without worrying about other replicas.
Contrastly, Spanner only performs replication after transaction execution.
Fault Tolerance
Spanner distributes shard leaders across all nodes, thus minimizing the impact of loss. A node loss means a loss of a subset of shard leaders, and replicas of these shreds find new leaders.
However, Calvin is very unforgiving in this case, If the node that hosts the global consensus lead, faces a loss, then the entire cluster becomes unavailable for writes till the new leader is available at a different node.
- Two-Phase Commit Procedure
Both Spanner and Calvin divide data into separate shards stored on separate machines. To guarantee the durability and atomicity of transactions, the ones that access data in multiple partitions must commit that every partition successfully processed it.
Since machines may fail independently in between, this procedure takes a two-round communication between the transaction and partitions involved. This two-phase commit often consumes latency for short and simple transactions because the actual processing time is much less than the delays involved in the two-phase commit.
Spanner’s cost of the two-phase commit is higher because it involves three forced non-overlapping writes to a log. Every write involves a cross-region Paxos agreement, causing the latency of the commit procedure about three times the Paxos’ latency.
- Determinism
Calvin avoids two-phase commit by using deterministic execution. Thus, machine failures do not abort transactions in this protocol.
Instead, the failed machine re-reads and replays the input transaction log from a checkpoint to recover its state at the time of failure, and continue normally. Thus, Calvin performs transactions in a single round of communication.
- Scalability
Major differences in the scalability are caused by the lock hold time. It also arises as the conflict rate between concurrent transactions increases.
Since Calvin’s commit procedure is shorter than Spanner’s, the former reduces the lock hold time at the transaction’s end. While it acquires all locks as the execution starts, Spanner performs all reads for a transaction before acquiring writing locks, thus, reducing lock time in the beginning.
Also, Spanner holds locks during replication. So, farther apart the regions, the larger the relocation latency, and therefore, the longer time for locks hold. In contrast, Calvin does not hold locks during replication because it performs replication during preprocessing.
Since Calvin holds the lock for a shorter time period, allowing parallel processing of conflicting transactions, it has higher throughput scalability than Scanner for transactional workloads.
- Transaction Models
With Calvin, the entire transaction should be submitted at once for deterministic transaction processing.
Spanner can support the full richness and complexity of SQL as it allows arbitrary client-side transactions. However, Calvin has a very restrictive transaction model that only supports a NoSQL client API.
Summary
Both Calvin and Spanner are exciting advancements in the database landscape. Each protocol has its own features and trade-offs.
Calvin derivative databases are ideal for distributed transactions with high concurrent access to the same data.
But, when it comes to single-row-or-shard-transaction heavy or public cloud, Spanner derivatives are inevitable. It allows developers to focus on the business layer without worrying about expensive and lengthy migrations in the database layer.
Although the Calvin and Spanner models will be with us for years, if history is any lesson, expect a new database theory to emerge in the next decade.