
When it comes to AI frameworks, there are several tools available that can be used for tasks such as image classification, vision, and speech. Some are popular like PyTorch and Caffe, while others are more limited. Below are the highlights of four popular AI tools.
Caffe
Caffee is a deep learning framework developed by Yangqing Jia while he was at UC Berkeley. The tool can be used for image classification, speech, and vision. However, it is not suitable for processing text, sound, and time-series data. The tool is a BSD-licensed C++ library that uses Python for its API. One of the areas that Caffe excels at is image processing where it can “process over 60M images per day with a single NVIDIA K40 GPU”. Caffe works well with feedforward networks but is not recommended for recurrent neural networks and sequence models.
In April 2017, Facebook created Caffe 2, adding more features to Caffe 1.0, including:
- Mobile deployment option
- Support for large-scale distributed training
- New hardware support (in addition to CPU, GPU, and CUDA)
- Support for quantized computation
- Everything was stress tested by Facebook applications
Operators in Caffe 2
The overall difference between operators’ functionality in Caffe and Caffe2 is illustrated below. In short, Caffe 2 has more than 400 different operators that can be considered as a flexible version of layers in Caffe 1.0. Operators contain the logic for computing the output for given inputs and parameters. One of the benefits, users can write their own customized operators.
Caffe Model Zoo
With Caffe Model Zoo, users can explore unique deep learning capabilities and build demo applications without intensive training. In the community, users can work with other developers to recreate use cases or improve existing models.
These models can perform tasks such as large-scale visual classification, simple regression, image similarity with Siamese networks, and robotics and speech applications.
Features of Caffe/Caffe 2
- Limited abstraction means you can easily do unconventional, hard-core modifications with familiarity with C++.
- Provides access to many new layer functions such as convolutions, maxout, ReLU, etc.
- Supports interfaces including C, C++, MATLAB, Python, and the traditional command line.
- Highly configurable and extensible at the prototype level and the source-code level.
Many established companies, including Adobe, Microsoft, Yahoo!, Samsung, Tesla, and Intel are using Caffe in uses cases involving image processing, vision, robotics, and language applications. In 2018, Caffe 2 was merged with PyTorch, a powerful and popular machine learning framework.
PyTorch
Facebook-developed PyTorch is a comprehensive deep learning framework that provides GPU acceleration, tensor computation, and much more. The tool is a Python version of the Lua-based Torch. The Python library provides packages for worker processes optimized for efficient data loading, distributed training, and deep learning functions.
The Python library provides two advanced features, including:
- Tensor (torch) computation with strong GPU acceleration:
Tensor is a generic n-dimensional array similar to Numpy arrays. It helps perform arbitrary numeric computation and makes the PyTorch projects run faster. The core data structure accelerates mathematical operations. Dimensions in Tensor are called ranks.
- Dynamic neural networks based on a tape-based autograd system (torch.autograd)
Autograd in PyTorch uses a tape-based system for automatic differentiation. In the forward phases, the autograd remembers all executed operations. In the backward phase, it replays these operations.
In addition to Tensor and autograd system, the most specific components of PyTorch are:
- torch.jit: This compilation stack creates optimizable and serializable models from PyTorch code.
- torch.nn: The neural network’s library is integrated with autograd for maximum flexibility.
- Torch.multiprocessing: Python multiprocessing with memory sharing across processes.
- torch.utils: DataLoader and other utility functions for ease.
Notable benefits/features of PyTorch are:
- PyTorch facilitates declarative data parallelism, wrapping modules using torch.nn.DataParallel.
- Users can freely use Python debugging tools such as ipdb, pdb and PyCharm to debug PyTorch code.
- The new hybrid front-end allows for two operation modes: eager mode and graph mode. Eager mode is used for research and development, while the graph mode provides improved speed and optimization in a C++ runtime environment, thanks to TorchScript.
- PyTorch has a large community of developers that are extending the ecosystem with more libraries and tools.
- Native ONNX (Open Neural Network Exchange) allows PyTorch-based models to directly access the compatible platforms.
- PyTorch allows developers to perform large-scale training jobs on GPUs, thanks to unmatched cloud support.
Scikit-learn
Scikit-learn is a popular Python machine learning library started by David Cournapeau in 2007. Scikit-learn is used in both academia and the commercial sector. The tool is built on SciPy, NumPy, and Matplotlib, and it supports IPython, Sympy, and Pandas. The reliable and well-maintained library boasts a rich suite of tools for predictive analysis and machine learning functions, from dataset loading and manipulation to preprocessing metrics and pipelines.
In addition, Scikit-learn has a large collection of supervised and unsupervised machine learning algorithms, most of which require minimal code adjustments. The tool is used for the following use cases:
- Classification
Scikit-Learn allows users to implement machine learning concepts with a well-documented, user-friendly, and robust library. The tool facilitates access to different classification algorithms such as nearest neighbors, random forest, and multi-labeling.
- Regression
Regression is the machine learning process for creating models to establish the connection between input and output data. Some popular regression algorithms are logistic regression, least angle regression, kernel ridge regression, and Stochastic Gradient Descent.
- Dimensionality reduction
Applicable for visualization and increased efficiency of machine learning models, dimensionality reduction reduces random variables for analysis. The algorithms include principal component analysis (PCA), truncated singular value decomposition, latent semantic analysis, and dictionary learning.
- Clustering
The sklearn.cluster module performs the clustering of unlabeled data. Each clustering algorithm has two variants:
- Class: Implements the right method to learn the clusters on train data
- Function: Returns integer labels for different clusters.
Clustering is used to perform customer segmentation and grouping experiment outcomes using various algorithms, such as spectral clustering, K-Means, Birch, DBSCAN, Agglomerative clustering, etc.
- Model selection and evaluation
Model selection compares, validates, and chooses models and their parameters. The modules perform model tuning for better accuracy, cross-validation, model persistence, validation curves, metrics, and scoring.
- Preprocessing
Scikit-learn preprocessing involves feature extraction and normalization to convert input data with machine learning. Its modules and algorithms include mean removal and variance scaling, non-linear transformation, normalization, encoding categorical features, and more.
Features of Scikit-learn:
- Accessibility and simplicity make it a beginner-friendly tool.
- The tool has a vast internal community of researchers and developers.
- It is suitable for businesses of various sizes. Companies such as JPMorgan, Spotify, Evernote, Booking.com, and AWeber use it
Spark MLlib
Spark Machine Learning Library (MLlib) was built on top of Spark and offers an extensive number of algorithms in the areas of classification, regression, decision trees, clustering, and more. Also, Spark runs in-memory thus making it highly performant. The tool can be used, in conjunction with other modules to perform feature transformation, extraction, and selection.
Spark MLlib enables iterative computing, which optimizes performance and the quality of results. The platform provides a distributed implementation of many ML algorithms with low-level primitives and utilities for convex optimizations, feature extraction, and linear algebra.
Features of Spark MLlib:
- Spark MLlib is usable in multiple programming languages, including Scala, Java, Python, and R.
- The algorithms and tools are 10 times faster on disk and 100 times faster in-memory than MapReduce.
- It is compatible with Hadoop, Kubernetes, Apache Mesos, standalone, or in the cloud.
- Spark MLlib has an ever-growing open-source community of industry leaders and developers that are constantly expanding the platform functionality.
TensorFlowOnSpark
Yahoo developed TensorFlowOnSpark (TFoS) in 2017 in order to bring the power of deep learning to Hadoop clusters using TensorFlow and Spark. Yahoo manages one of the largest Hadoop clusters in the world that’s nearly 500PB. TFoS combines the features of Apache TensorFlow and Apache Hadoop, enabling distributed deep learning on CPU and GPU servers clusters.
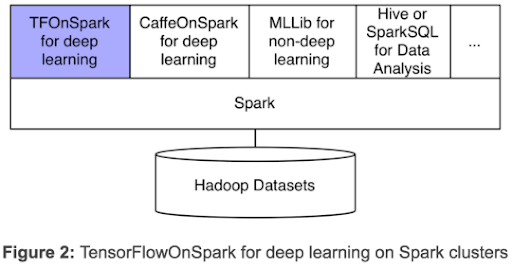
As shown in this figure, TensorFlowOnSpark works with Spark libraries, including SparkSQL, MLlib, etc, in a single program.
The following diagram shows the architecture of TensorFlowOnSpark:
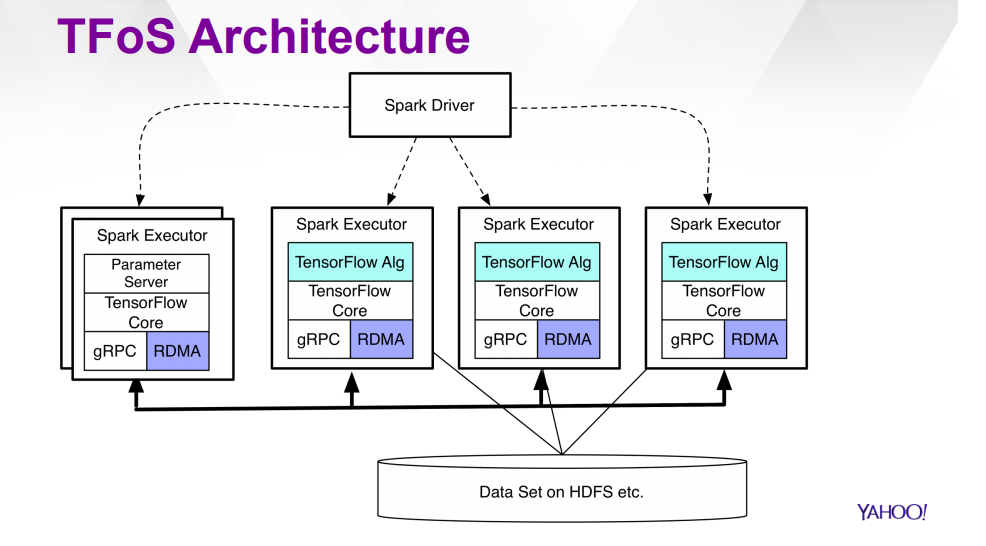
TensorFlowOnSpark has two modes for data ingestion which include TensorFlow QueueRunners and Spark Feeding. The former reads data from HDFS files using file readers of TensorFlow and QueueRunner. On the other hand, Spark Feeding involves feeding iSpark RDD to Spark executors that feed it into the TensorFlow app
Features of TensorFlowOnSpark:
- TensorFlowOnSpark supports all functionalities offered by TensorFlow including model/data parallelism, inferencing, synchronous/asynchronous training, and TensorBoard.
- It allows direct server-to-server direct communication to yield faster learning.
- Developers can easily integrate the AI framework with existing data processing pipelines.
- Companies using TFoS: Airbnb, Coca-Cola, Dropbox, SAP, Intel, and AMD.