

Kubernetes has become the standard for deploying and managing containerized workloads. It’s simple to work with when workloads are basic and complex when multiple clusters and multiple regions are required. Add Istio to the mix, and complexity reaches a new level. Fortunately, there are tools available to help manage complexity. Below, we’ll take a look at five tools that provide a rich set of capabilities in the areas of automation, metrics, logs, monitoring, setup, scaling, and more.
Keptn
Keptn is an event-driven control plane that automates continuous delivery for cloud-native applications. The tool helps users define software delivery and operations processes declaratively, helping solve problems associated with continuous software delivery.
Delivery pipelines are used to automate the rollout of new features, thus minimizing the amount of manual work required to maintain software. However, when pipelines are designed manually, they become complicated over time because of mixed information about target platforms, processes, and environments. Also, there is no clear separation of concerns, as users use the pipeline for different purposes.
Keptn helps with automating CI/CD pipelines in Kubernetes deployments. Now, teams spread across geographic locations don’t need to build their own customized CD pipelines and spend time maintaining them. Instead, the tool provides a clear separation of concern, allowing developers, DevOps, and SRE’s to independently update delivery pipelines. Using Keptn, developers can focus on coding instead of developing thousands of configuration files.
Keptn Architecture and Core Components
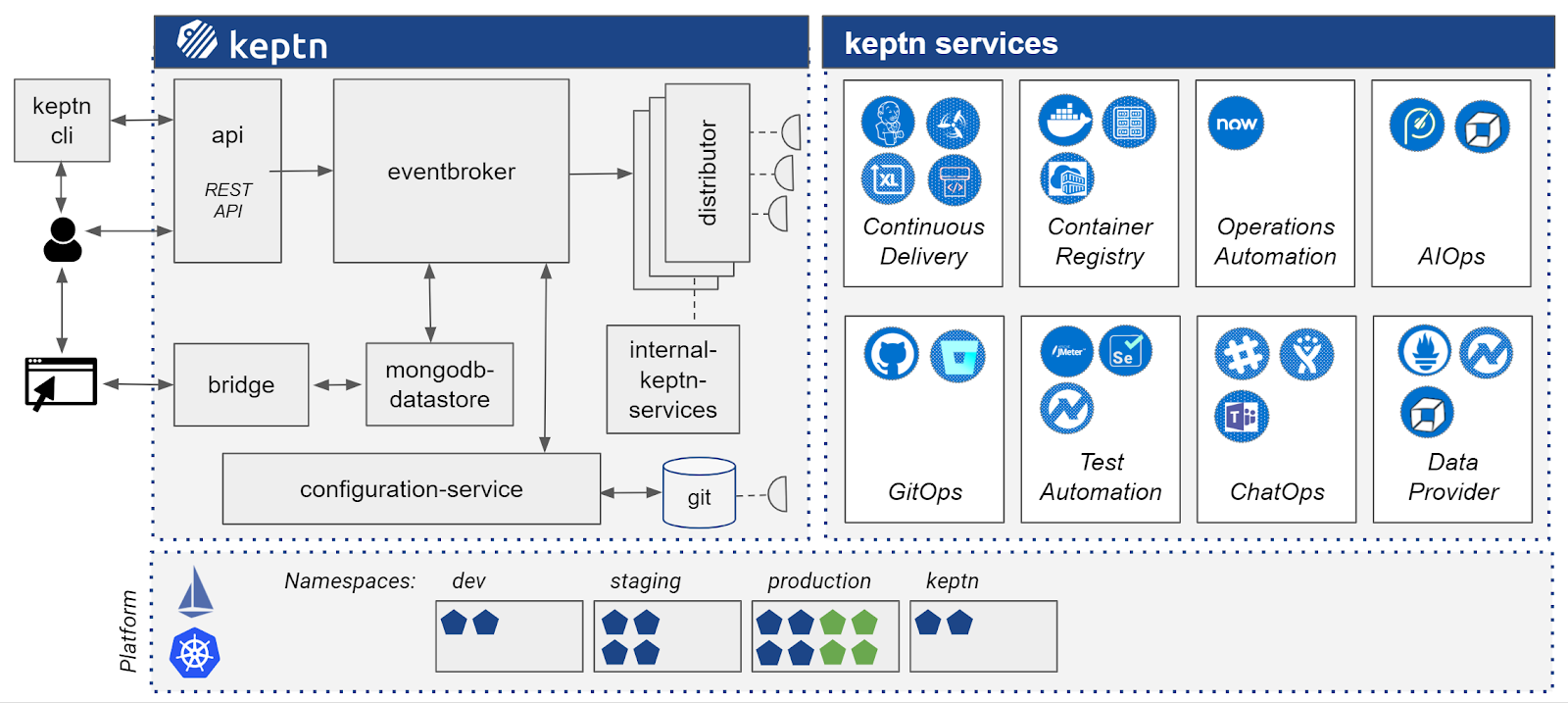
The core components include the following:
- Keptn CLI: The Keptn CLI sends commands to Keptn, which is installed on a local machine.
- API: Communication is done via a REST API. The API consists of a websocket server that forwards Keptn messages to the CLI.
- eventbroker: Eventbroker receives all event data. It separates and forwards non-Keptn events to the relevant Keptn Cloud Events and NATS.
- distributor: Receives event messages from NATS and forwards the events to services that have a subscription to the event topic.
- mongodb-datastore: Provides storage for event and log data in a mongodb available on the Keptn cluster.
- bridge: Provides a user interface to allow users to browse the log files and the interface shows all log messages for events.
- configuration-service: Manages resources for project-related entities with version control using a Git repository.
KEDA
By default, Kubernetes scales according to operational metrics such as memory and CPU but doesn’t consider application-level metrics like messages on a queue awaiting processing. As a result, developers must create HPA (Horizontal Pod Autoscalers) to define how their deployments should scale.
To achieve this, developers need to pull the metrics from desired sources, and that becomes challenging when multiple sources are involved. KEDA is a tool that helps in this process, as it scales event-driven workloads and allows users to leverage external metrics to define the tasks based on information from any event source.
Users can easily deploy this lightweight component to any Kubernetes cluster. It also works with other Kubernetes components and can extend its functionality without overwriting. This flexibility allows users to specify the applications that need scaling.
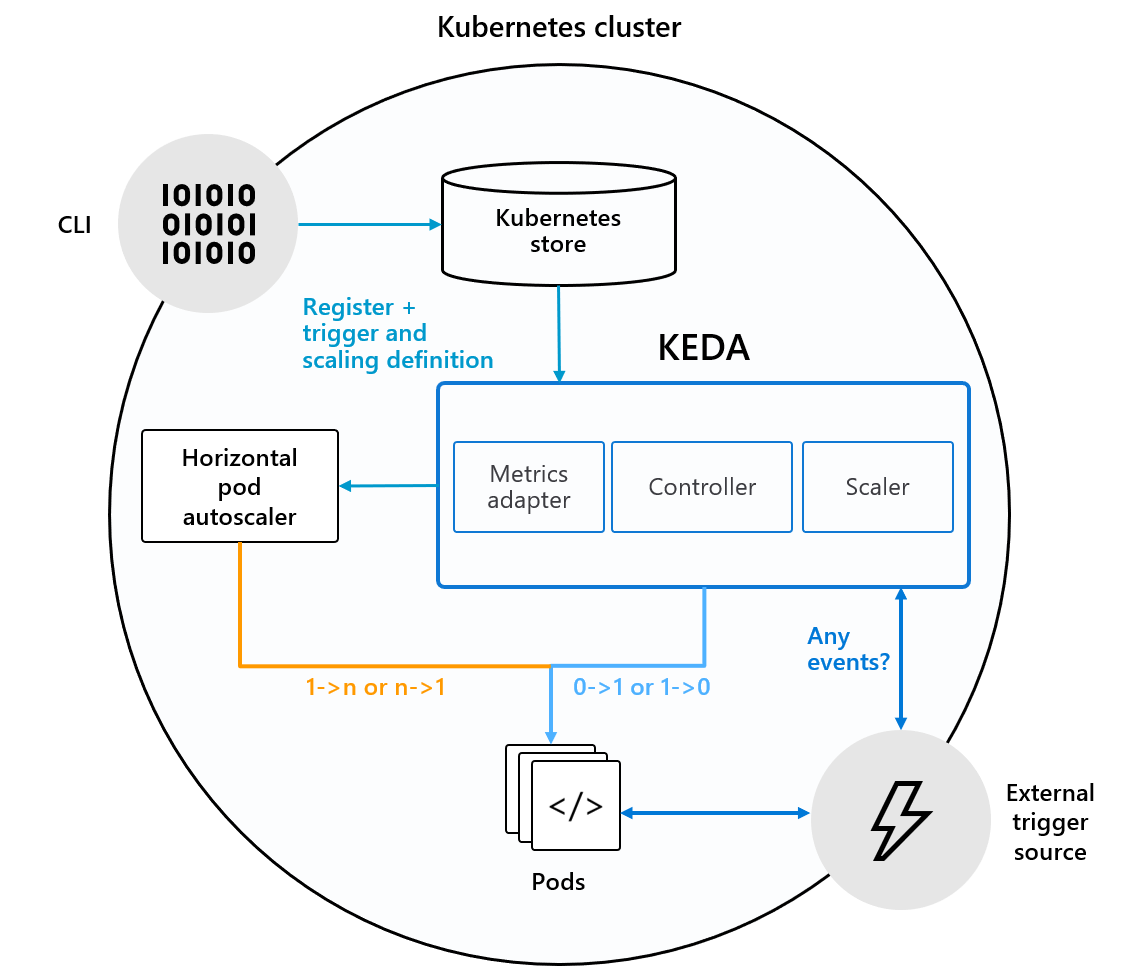
KEDA provides three components in each Kubernetes cluster:
Scaler
This component connects to the selected source and reads its metrics. Scaler is defined by a ScaledObject manifest that further defines an external source or trigger. It uses this information to fetch the required metrics and forwards them to the KEDA metrics server.
Some of these scalers are:
- Apache Kafka
- Redis
- Azure Service Bus
- Google Cloud Platform Pub/Sub
- Prometheus
KEDA offers advanced scalers for various databases, vendors, messaging systems, etc.
Metrics Adapter
Metrics Adapter forwards the read metrics from external sources to HPA and enables horizontal app autoscaling.
Controller
It provides scaling from 0 to 1 or vice-versa to the container’s consumer. Controller scales only to the first instance. HPA handles further cloning using metrics received from the Metrics Adapter.
Once you have installed KEDA on a Kubernetes cluster, users can use it to:
- Create a Deployment: This is the software that needs to be scaled according to a scale trigger.
- Create a ScaledObject: With this custom resource definition, you can define the autoscaling criteria and sources of metrics.
After that, KEDA collects information from event sources and performs autoscaling accordingly.
KEDA also works seamlessly with Microsoft Azure Functions runtime to provide event-based Kubernetes scaling.
Kudo
Kubernetes Universal Declarative Operator (KUDO) is an open-source toolkit that facilitates a declarative approach to developing production-grade Kubernetes operators. While Kubernetes already has built-in automation to run workloads, complex scenarios involve manual intervention and that’s the area KUDO helps with.
KUDO uses Kubernetes objects to provide abstractions for sequencing lifecycle operations. It features a kubectl plugin and command-line client, which allows users to manage, deploy, and debug all kinds of workloads that are further managed as CRDs, storing everything in a repository with versioning.
KUDO helps DevOps teams manage day 2 operations on Kubernetes. It supports service upgrades along with recovery, backup, and the needs of observability.
KUDO Architecture
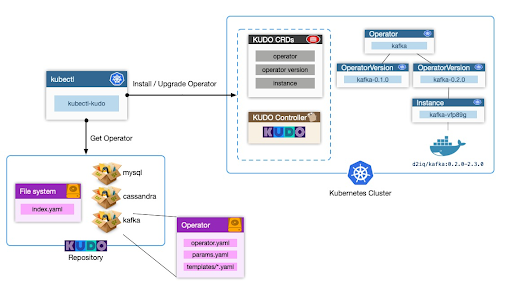
The most important KUDO components are:
- Operator Package: It’s a collection of files that define KUDO operators. It can be local or remote and has all the Kubernetes resources and definitions needed to run the application.
- Repository: It holds all operator packages in a local folder or a remote URL. It also provides an index of operators each with appropriate URLs. Some of KUDO repositories are Redis, MySQL, Apache Spark, Elastic, and Kafka.
- KUDO Manager: It refers to a set of Kubernetes controllers that manage and execute KUDO operators.
- Plan: The main workflow unit of operators defines the steps that apply Kubernetes resources to the cluster in a specified order.
In addition, KUDO also uses OperatorVersion and instances to handle workloads. OperatorVersion refers to the implementation of a particular version of an Operator. The version contains plans, objects, and parameters.
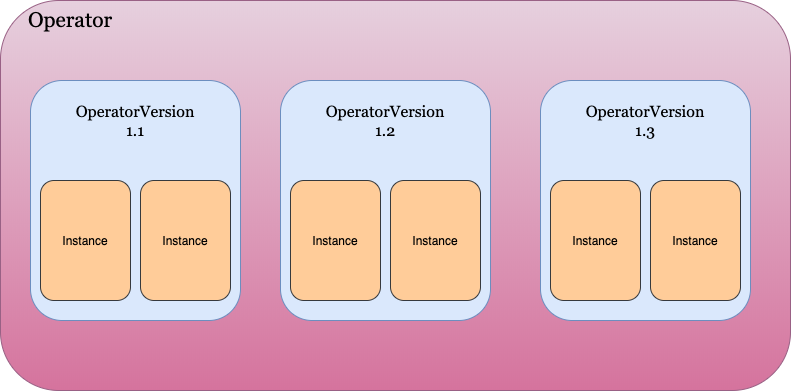
Instance renders parameters in templates, including pods, services, or StatefulSets. Users can build multiple instances of OperatorVersions on Kubernetes clusters.
Using Kudo, application administrators can run their applications on Kubernetes without learning the core concepts of Kubernetes. DevOps can easily write operators without writing lengthy code. It also provides an effective means to standardize the way users manage operators.
Kuma
Kuma is a universal control plane designed for Service Mesh and Microservices. Built upon Envoy, Kuma runs natively on Kubernetes and reduces the amount of code required for building reliable architectures. Kuma “can instrument any L4/L7 traffic to secure, observe, route, and enhance connectivity between any service or database.” This model requires a control plane that allows users to configure proxies dynamically without manual configuration.
Kuma Deployment Models
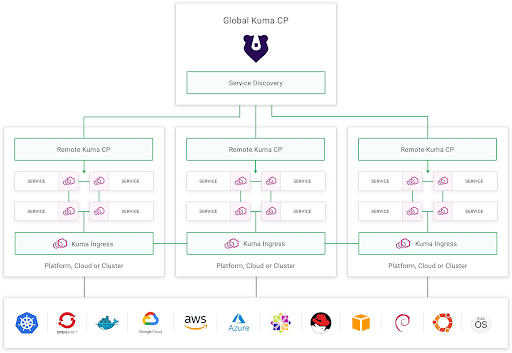
Kuma supports flat deployment and distributed deployment models. Flat deployment involves one control plane that handles multiple data plane proxies. On the other hand, the distributed deployment model features a global and remote control plane for every Kubernetes cluster.
In both models, Kuma Ingress Resources and DNS Service Discovery have been abstracted away, automating service-to-service connectivity. The following illustration shows a distributed deployment enabling Kuma to set up a service mesh that runs simultaneously on Kubernetes clusters:
Kuma 0.6
Recently, Kong Inc. has announced Kuma 0.6 with major improvements and additional support for service meshes that span across platforms, multiple clouds, and multiple clusters.
This newest version features a powerful ‘hybrid universal mode’ that helps support complex applications running in a heterogeneous environment. It accelerates the process of digital transformation and business agility by making it easy to manage and secure connectivity across the organization.
Key features of Kuma 0.6 are:
- Automated Service Connectivity: Kuma 0.6 automates and abstracts service mesh connectivity across all enterprise platforms.
- Advanced Control Plane Replication: It supports global and remote control plane replication for better scalability and operational visibility.
- Hybrid Multi-Mesh Support: Kuma 0.6 runs in the native multi-mesh and multi-tenant mode, allowing organizations to create flexible service meshes for any use-case.
- New Ingress Data Plane: A new ingress data-plane mode automates and eases cross-cluster and cross-platform service mesh communication.
Volcano
Volcano is a batch computing system built on Kubernetes. It provides a mechanism for running high-performant batches and workloads, including machine learning, deep learning, bioinformatics/genomics, and other big data software programs.
These programs largely run on generalized domain frameworks, including Spark, TensorFlow, PyTorch, and more, supported by Volcano.
Architecture of Volcano
Volcano adds many features, services, and mechanisms to Kubernetes. These mechanisms and services include scheduling extensions, job management extensions, and accelerators like GPU and FPGA, Kubernetes enhancements, and more.
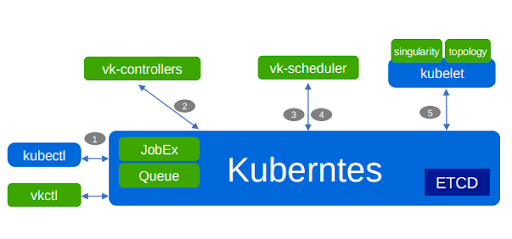
Volcano steps for Pod creation:
Step 1: Kubectl is a command-line tool for controlling Kubernetes clusters. It creates a JobEx object in the apiserver after passing admission.
Step 2: JobExController creates Pods according to its templates.
Step 3: apiserver notifies vk-scheduler about Pod.
Step 4: vk-scheduler selects a host for the Pod according to its policy.
Step 5: kubelet gets the Pod notification from apiserver, and starts the container.
Volcano is a new generation batch computing system that supports two-level scheduling and provides a centralized scheduling mode. In addition, Volcano supports integration with several computing frameworks, such as KubeFlow, Apache Spark, and KubeGene.
During Kubeflow integration, kubeflow / tf-operator leverages the scheduler part of Volcano, while kubeflow/arena uses job scheduler and job management. Kubeflow simplifies the deployment of diversified machine learning workloads.
When integrated with spark-operator, it uses only the scheduler part, including ongoing integration with spark-on-Kubernetes. Spark provides high-level APIs and an optimized engine to support big data analysis.
KubeGene simplifies the genome sequencing process on Kubernetes while making it portable and scalable.