
Load balancers play a critical role in helping enterprises scale internet infrastructure. At the most basic level, load balancers ingest incoming internet traffic, then distributes the load across server infrastructure, as was the case when Google helped Niantic launch Pokémon Go in 2016. In short, they act as middle-men managing incoming traffic so the backend infrastructure doesn’t get overwhelmed and break down.
There are several open-source options available in the market, from the very popular HAProxy to Katran. Each one is best suited for a specific use case. We’ll take a look at several and highlights their key features. First, let’s start off with the basics.
Load Balancing 101
Load balancers use different techniques and algorithms to manage the process of ingesting and distributing traffic. The various steps in a request/response life cycle are as follows:
- A client such as a browser or application tries to connect with a server and initiates the process of request/response.
- Load balancers receive the request and route it to one of the servers in a server group.
- The server responds to the client through the load balancer.
- After receiving the response, load balancers match the client’s IP with the IP of the selected server. Then, it transfers the packet with the response.
- As configured, load balancers may decrypt data using the Security Socket Layer (SSL) encryption protocol.
The process repeats until the entire session is over.
Now, let’s start by looking at Neutrino.
Neutrino
Neutrino was developed by eBay in 2016. One of the goals of the new product was to replace expensive proprietary hardware that was inflexible within their particular environment. Built on Netty and Scala, this cloud-ready load balancer was developed to do Layer 7 (L7) switching. As a run-time environment, it uses the Java Virtual Machine, and runs smoothly on any commodity hardware, given the availability of JVM 7+.
Neutrino has the capability to perform L7 routing using URL context, canonical names, and rules. It features a highly extensible pipeline architecture that allows new modules to be hooked into the provided pipeline in a hassle-free manner. Developers can expand it by adding new load-balancing options and switching rules easily.
New modules are added to load the configuration file from an API or a database or to send logs to API endpoints. Since the tool uses the JVM run-time environment, you can use either Scala or Java to add new modules.
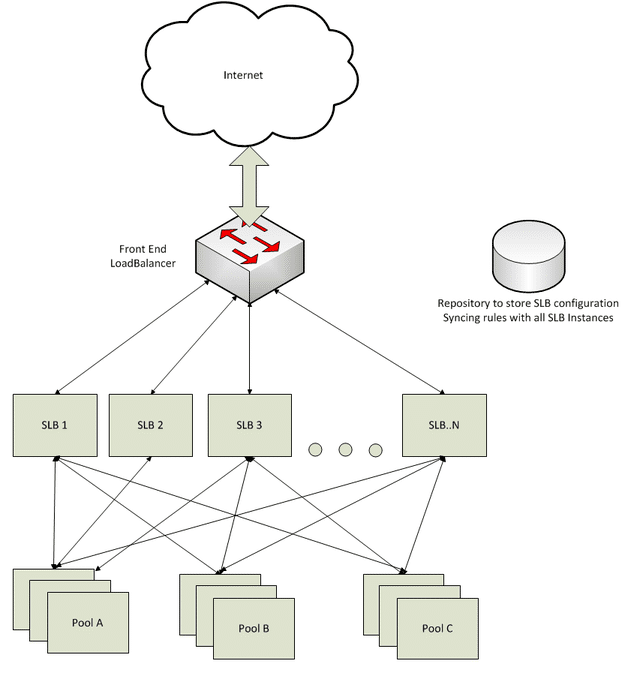
Neutrino SLB (software-based) is preferred for its programmability and high customizability. Distributed as a jar file, it can run with other applications or as a standalone.
Load Balancing Options
Neutrino support two options:
- Least Connection: When a load balancer uses the least connection method, it chooses the server that has the least number of active connections. It helps the load balancer to ensure that the overall load of the active requests is well-balanced on the servers.
- Round Robin: It is one of the simplest methods for distributing client requests across servers. While going down the list of servers in the group, this tool forwards a client request to every server in response.
Switching Options
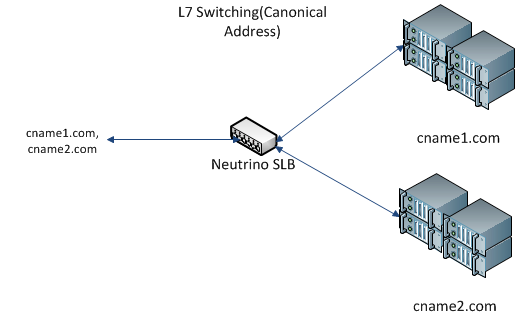
- L7 Switching: Developers can achieve L7 Switching using canonical names. Every HTTP request features a URL address in the HOST header. Neutrino looks at the header and routes the traffic to an appropriate pool.
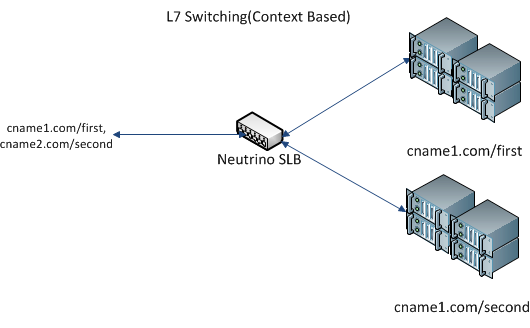
- L7 Context-Based Switching: This type of switching involves using URL suffix and canonical names. It is extremely useful when using the same canonical names for two services, each with a different URL suffix.
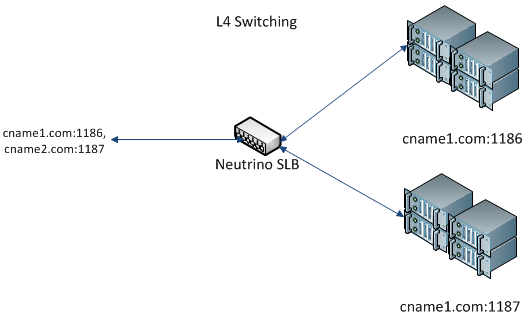
- L4 Switching: Users can achieve L4 Switching using multiple port numbers. Each service is identified using a port number, and traffic at each port number is sent to each pool.
Neutrino can run in a VM or a Docker container. Built as a library, Neutrino can be easily integrated and shipped with third-party applications.
Maglev
Maglev is Google’s network load balancer that operates on commodity Linux servers. The distributed software system does not need a specialized physical rack deployment. Developers can adjust its capacity easily by removing or adding servers.
Network routers use Equal Cost Multipath (ECMP) to distribute all available packets evenly to the Maglev machines, each of which matches the packets to their associated services and spreads the packets evenly to the service endpoints. To cater to ever-increasing traffic, Maglev is optimized for high-performance packet processing. One Maglev machine can saturate about a 10Gbps link with small-sized packets.
Maglev also features consistent hashing and connection tracking that help minimize the negative effects of unforeseen failures and faults on connection-oriented protocols.
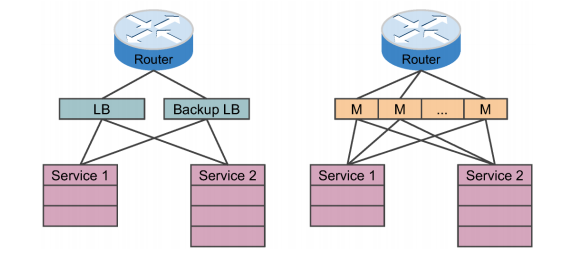
Frontend Serving Architecture of Maglev
Maglev is deployed in various Google data centers around the world. It includes clusters of different sizes, as shown in the following figure:
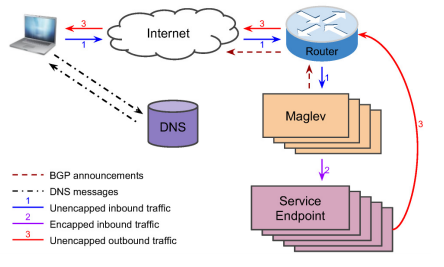
Every Google service consists of one or more Virtual IP addresses (VIPs) that are served by multiple service endpoints. Maglev links each VIP with service endpoints and notifies the router over BGP of the same.
In response, the router announces the VIP to the backbone of Google. VIP network aggregations are notified to the Internet to make them accessible worldwide. Maglev can handle both IPv6 and IPv4 traffic.
Packets at the selected service endpoint are decapsulated and consumed. The response is entered into an IP packet with VIP serving as the source address and the destination address being the user’s IP.
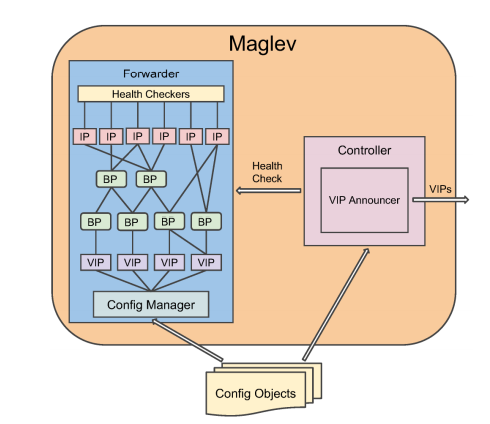
Unlike traditional load balancers, Maglev provides 1+ redundancy, making it highly reliable. It only uses existing servers inside the clusters, thus simplifying the deployment of the load balancers.
Katran
Katran is Facebook’s second-generation L4LB that powers its network infrastructure with a software-based approach and an entirely re-engineered forwarding plane.
The plane leverages two recent advancements in kernel engineering:
- eXpress Data Path (XDP): This provides a programmable network data path without resorting to a full-fledged kernel bypass method. It runs along with the Linux networking stack.
- eBPF virtual machine: It provides an efficient, flexible, and reliable way to interact with the Linux kernel. By running user-space supplied programs at particular points in the kernel, eBPF extends its functionality. eBPF brings dramatic improvements to several areas, such as filtering and tracing.
Katran is deployed on backend servers in Facebook points of presence (PoPs) which helps the giant improve the scalability and performance of its network load balancing infrastructure while reducing inefficiencies.
When it comes to the architecture, ExaBGP first announces the VIPS to a specific Katran instance that is responsible for handling it. Next, an ECMP mechanism is used to send packets destined to a VIP to Katran instance. Finally, Katran chooses a backend and forwards the received packet to the correct backend server.
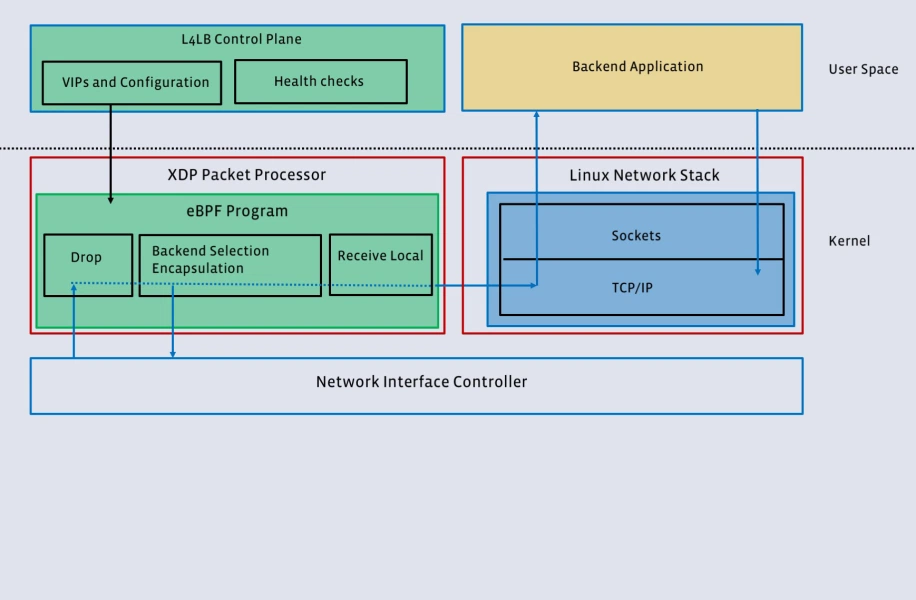
Katran uses XDP and a BPF program for packet forwarding that enables early and efficient packet handling. It uses the extended version of the Maglev hash to select a backend server that allows for more stable and inexpensive hashing.
Another important consideration of Katran is RSS-friendly encapsulation. Receive Side Scaling (RSS) steers packed from each flow to an individual CPU, resulting in uniform load distribution across CPUs.
Seesaw
In 2012, Google’s Site Reliability engineers developed Seesaw in Golang (GO) to achieve an unmatched level of scalability. This robust, open-source load balancer mainly does the following:
- Load balances with DSR (or DR) and NAT
- Handles traffic for anycast and unicast VIPs
- Conducts adequate health checks
Seesaw is based on Linux, and it provides load reliable balancing service for servers installed on the same network. Some of its notable features are type safety, garbage collection from memory, key-value mapping, an extensive standard library, to name a few.
Anycast
Seesaw fully supports anycast VIPs. To install and configure it, Seesaw uses the Quagga BGP daemon. It also uses BGP peers that accept seesaw-advertised host routes.
The load balancer uses two Seesaw nodes, each of which features two network interfaces. One of these network instances supports the host, while the other supports cluster VIP. It uses layer 4 networking techniques with DSR and NAT.
Traefix
Written in Golang, Traefik is a modern HTTP reverse proxy, edge router and load balancer that makes it easy to deploy microservices. Since the load balance configures itself dynamically and automatically in real-time, there is no need to maintain and synchronize an individual configuration file. Instead, time and energy can be focused on developing new features.
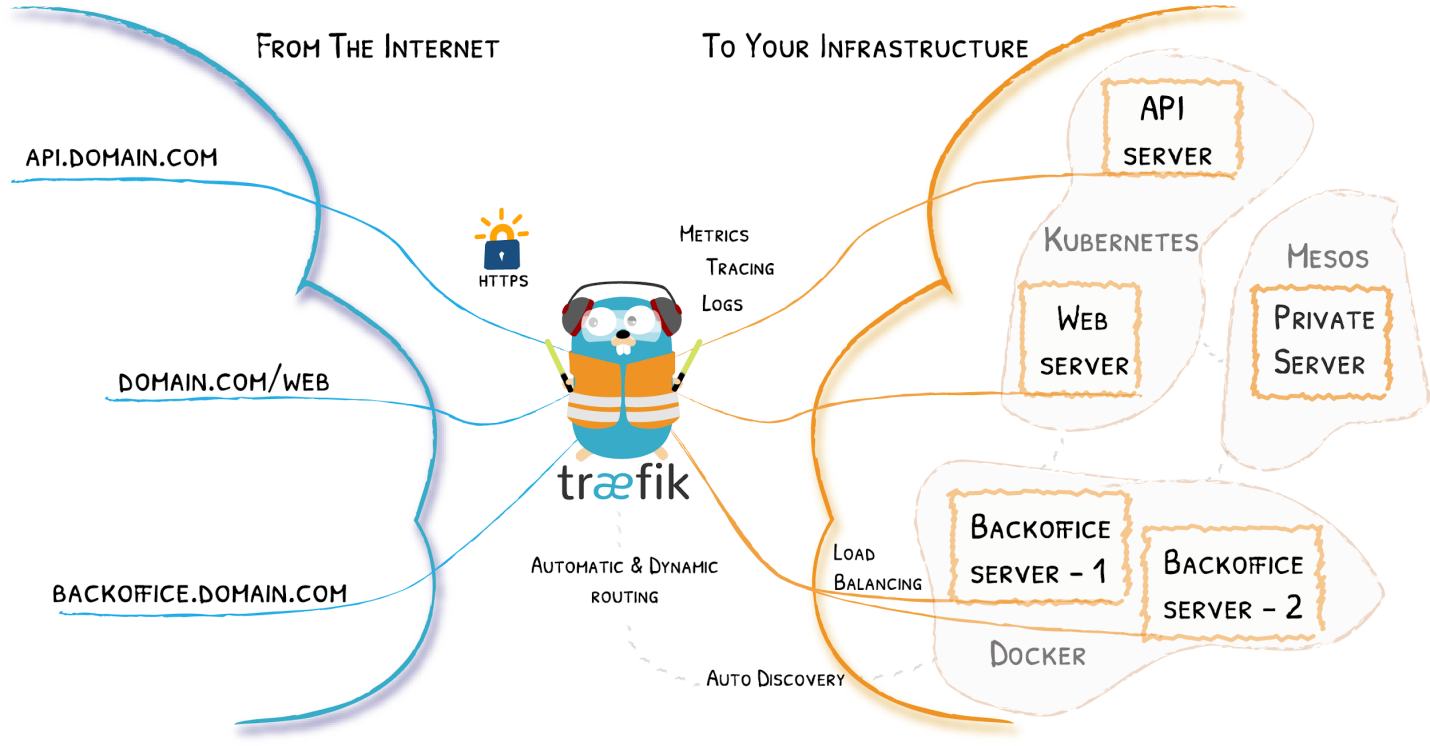
Traefik Active Load Balancer
The “active mode” load balancer uses rancher-metadata and Docker labels. It scans rancher-metadata and provides access to services that configure specific labels. Traefik helps obtain these features. It works in conjunction with the existing infrastructure components, such as Kubernetes, Consul, Docker, Rancher, Amazon ECS, etc.
Traefik has a zero downtime reload, and it may define circuit breakers’ rules. It uses default parameters to run in all hosts that have label traefik_lb=true.
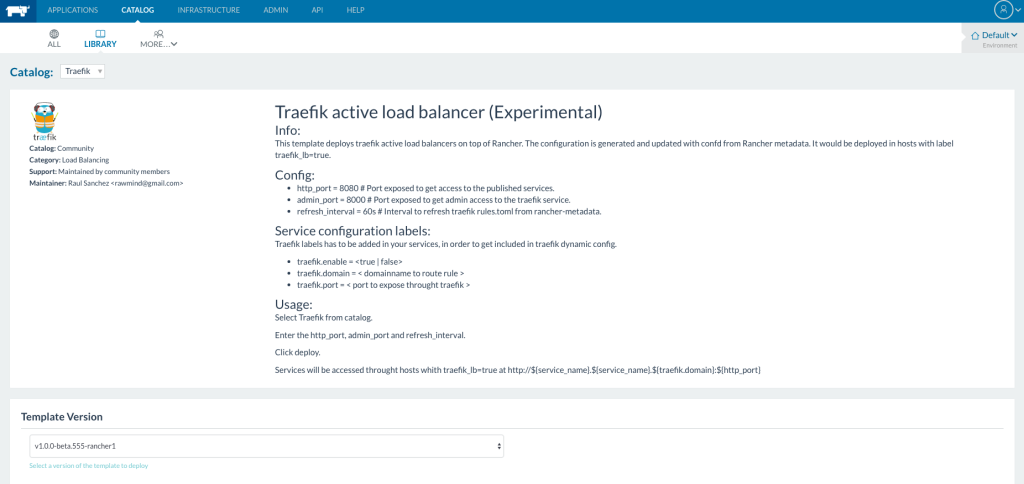
After it deploys the service, the admin interface becomes accessible at http://host-address:9000. Users have to define these labels at the service to make services automatically exposed at Traefik:
- traefik.enable = <true | false>
- traefik.port = < port to expose through traefik >
- traefik.domain = < domainname to route rule >
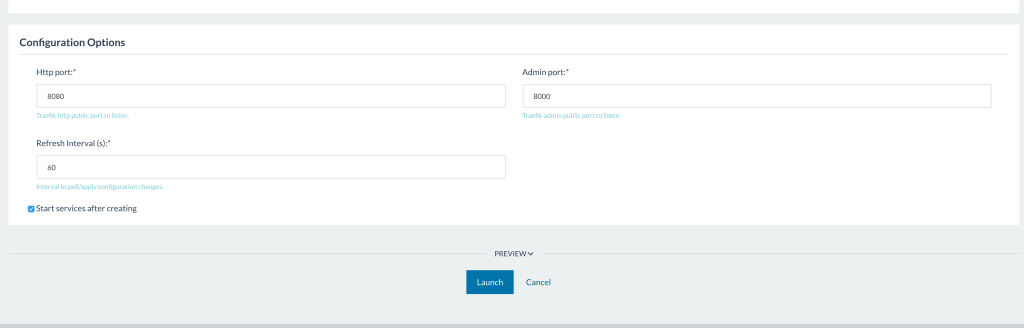
A health check has to be defined in the service because only healthy backends are added to Traefik. Defining traefik.enable = true label without the defining a health check for a service causes the frontend to be added to Traefik with a blank list of backends.
HAProxy
HAProxy (High Availability Proxy) is a fast and reliable TCP/HTTP load balancer. It’s also the most popular product on the market and ideal for websites that receive a massive amount of traffic. It runs both on layer 4 and layer 7, and distributes the workload evenly across multiple servers, thus improving the performance of servers.
HAProxy can be easily integrated into almost any architecture, without exposing web servers to the net, as shown in this figure:
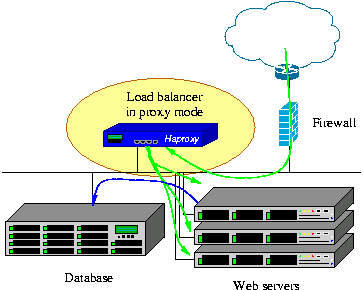
Source: HAProxy
The latest version 2.1 has advanced features, such as improved debugging, FastCGI, better multi-threading, to name a few.
Written in C programming language, HAProxy reduces the cost of memory usage and context switch.
Supporting Platforms: Linux 2.4, Linux 2.6-5.x, Solaris 8/9, Solaris 10, AIX 5.1 – 5.3, OpenBSD 3.1 to -current, and FreeBSD 4.10 – current.
- Event-Driven Architecture
The event-driven architecture handles all incoming connections while minimizing RAM and CPU consumption. ‘Single-buffering’ saves memory bandwidth, allowing the load balancer to simultaneously process a multitude of requests without latency.
- High-Level Security
ACL, flexible configuration, stick table systems, and map makes HAProxy Enterprise Edition protect against threats like vulnerability scanning and web scraping. It provides security to web servers by redirecting your HTTP traffic to HTTPS. HAProxy also performs SSL termination, that is, it decrypts SSL traffic during load balancing.
- Customizable
Another fascinating thing about HAProxy is that the load balancer is customizable. Put simply, you can uniquely configure it to distribute traffic across server nodes. You can combine various algorithms, such as Least Connection, Round Robin, URI, and many more, based on your requirements.
With the server monitoring dashboard, you can track the health of various server nodes. The dashboard also provides real-time aggregate stats so that you can detect bugs and errors quickly and easily.
Summary
Load balancers help enterprises scale modern internet infrastructure to support any workload. Load balancers were created to solve a specific problem. For instance, if an environment supports containers and microservices-based architecture, Traefix is a great fit. If millions of requests are hitting the back-end infrastructure on a never-ending basis, Katran and HAProxy might be the right solution.